引言
一个现代的大型门户信息系统中通常拥有数个功能相对独立的子系统,每个子系统中都存在大量的异构的数字资源,这些资源在物理位置上可能是集中式的,也可能是分布式的。一般来说,这些子系统都分别拥有自己的检索系统,这样虽说给开发和管理上带来方便,但是却给用户在同时检索各种资源时造成了极大的不便。如何组织和管理海量的数据资源,向用户提供统一友好的查询界面,成为大型门户信息系统面对的重要课题。
而对于一个大型企业门户信息系统来说,由于企业中众多的部门和人员配置以及复杂的业务流程。更会产生大量的电子文档与资料。面对如此海量的异构数据信息,传统的检索平台只是根据每个企业特定的业务流程,开发对应的检索服务。这样做不但使检索平台难于复用,而且对系统中海量的数据信息也是一种巨大的浪费。
本文提出的统一检索平台,将子系统检索、基于SRW协议的检索与全文检索相结合,再将其包装为WEB服务,这样该平台既可以很方便地复用,又可以针对各种数据类型进行检索,很好的满足了现代大型企业信息系统的检索需求,该系统目前已经应用于南水北调中线干线信息系统,取得了良好的效果。
1 统一检索相关概念
1.1 统一检索
统一检索:以多个分布式异构数据源为对象,向用户提供统一的检索接口,将用户的检索要求转化为不同数据源的检索表达式,并发地检索本地、局域网和广域网上的多个分布式异构数据源,并对检索结果加以整合,在经过消重和排序等操作后,以统一的格式将结果呈现给用户的检索。目前,异构数据源统一检索在国内外都受到了广泛的关注,主要的有ZING协议(SRW协议、CQL查询语言等),全文检索等等。
1.2 ZING协议
ZING是Z39.50-International:Next Generation协议的缩写。提出ZING的目的是适应新的信息技术发展的形势,消除Z39.50的实现障碍,使Z39.50协议的内容得到更广泛的应用。它主要包括SRW,CQL,Zoom,ez3950和ZeeRex五个部分。SRW是一个基于XML的、用于Internet的信息检索和获取协议。CQL是Common Query Language的简写,它是一种正式的检索语言。可以向检索系统发出检索请求,其检索表达式可以映射到具体的检索系统中去。
1.3 全文检索
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。有时,为了避免检索结果重复率过高,可以采用消重算法。
2 统一检索平台架构设计
2.1 统一检索平台需求
一般的大型门户信息系统对统一检索平台都有如下要求:
·检索平台能跨越各功能模块之间的差别,屏敝模块之间的界线,在整个门户系统中进行检索。
·对各种资源书目都能进行检索.同时对于文本文档还支待全文检索。
·检索结果安全显示,即检索结果的读写权限与系统保持一致。
·实时性保证,尽量做到即发即查,信息一旦进入系统,即可在统一检索平台中查询得到。
·良好的可移植性,在功能实现上尽量使用抽象方法,在不同的门户系统中对其进行具体实现,使统一检索平台可以方便的移植到其它大型门户信息系统中。
2.2 统一检索平台结构设计
根据以上要求,本文设计的统一检索平台的结构分为三层,分别足请求转发层,统一检索业务层(以下简称为业务层)与数据库层。请求转发层从用户方面接受请求,对其进行分析及初步检验。业务层接收经过合法性验证的查询请求,在业务层,根据用户需求,将其包装为不同的查询格式,分别为针对元数据进行的基于SRW协议的检索、全文检索、以及子系统API检索。数据库负责存储各种形式的数据,在本系统中,包括关系数据库,多媒体数据,以及全文检索库。其中,多媒体数据和全文检索的文档的书目信息,也要保存在关系数据库当中。该检索平台以SRW协议和全文检索机制为核心设计,并可以兼容子系统API检索,整个系统管理和维护相对简单,且各模块节点独立性高,系统可靠性强,扩充简单。检索平台结构图如图1所示。

图1. 检索平台结构图
3 基于SRW协议的检索服务实现
3.1 请求服务
SRW对于查询定义了3种操作:Search Retrieve,Explain,Scan。在本系统中,我们实现的是Search Retrieve操作。请求服务格式如表1所示:
表1. 请求服务格式
3.2 应答服务
由于SRW协议是不区分服务器与数据库的,因此我们需要在业务服务器自己实现对数据库的查询,然后将查询结果封装为Web服务,返回给客户端。应答服务封装格式如表2所示:
表2. 应答服务格式

4 全文检索服务实现
开源社区中相关工具比较多,比较成熟的开发工具有Lucene。但是Lueene是针对英文开发的,因此,针对中文分词需要有自己的工具。在此,我们采用了中科院的ICTCLAS,取得了很好的效果。
本部分的重点将集中在文档的消重处理上。在大型信息系统中,会有很多内容重复的文档在各个子系统中互相转载,此时,如果用户检索后,一一下载查询,会浪费很多不必要的时间。在此,我们经过对现有算法的分析之后,提出了一种基于关键词的权值向量空间的比较方法。首先做出如下定义:
1)用Pi表示第i个文档
2)其权值最高的前N个关键启事构成的特征项集合为Li={t1,t2,…,t3}
3)其对应的特征向量为wi={wi1,wi2,…,Wim}
4)前N个关键词拼接成的字符串用Concatenate(T1)表示
5)前N个关键词按字母序排序后再拼接成的字符串用Concatenate(sort(T1))表示。
6)用MD5(X)来表示字符串X的MD5散列值,
7)用Mirror(Pi,Pj)表示Pi,Pj互为转载文档,
8)用A→B表示“若A成立则B成立”
我们首先使用公式:
(MD5(Concatenate(sort(Ti)))=MD5(Concatenate(sort(Ti))))Mirror(Pi,Pj)
该公式表明.当两个网页的权值最高的前N个关键词集合相同时,就认为两者是互相转载的文档。但是,经试验后发现,该算法并未考虑到这些特征项所构成向量的夹角大小。因此,在此算法的基础上进行了改进,定义了两个文件特征向量的相似度S:
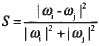
由公式可以看出,S能够同时兼顾向量的夹角和长度的两个因素。当两个文件的内容毫不相关时(即它们的关键词集合没有交集),wi与wj垂直,S的值为1。当两个文件相同时,S为0。这样,S的值成为判断两个文件相似度的标准。
5 统一检索服务实现
统一检索平台向用户提供统一检索服务,它实际上整合了“基于SRW协议的检索服务”以及“基于全文检索的服务”以及“子系统检索”三个部分。向用户提供更加抽象的接口。统一检索服务消息格式如图2所示。

图2. 统一检索服务消息格式
在SRW协议之前,增加了一个字段叫做RetriereType,它用来表示检索类型。如果是基于全文检索的查询,还需要在SRW协议格式之后增加一个字段叫做IsFiher,它用来表示是否对全文检索结果进行查重过滤。全文检索的表达式借助与SRW协议中的query字段来实现,这样可以实现最大限度的复用。其具体流程如图3所示。
6 本文小结与作者创新点
本文分析了目前大型企业门户信息系统中统一检索平台的现状,并在此基础上提出了统一检索平台的基本需求。该平台与一般的统一检索平台只针对元数据进行查询不同,而是针对企业门户信息系统的特点,将子系统检索、元数据检索和全文检索机制相结合,并将其结果以统一形式返回。该平台能够很好的满足现代大型门户信息系统中各种查询需求。并且,在系统中采用了消重机制.减少了信息的冗余。系统中采用了WEB服务的方式,降低了耦合度,提高了扩展性和移植性,适合运用于各种门户系统,具有广泛的应用价值。目前,该系统已经成功应用于南水北调中线干线建管信息系统。据南水北调中线干线建设管理局的统计,由于该系统的实施,带来人力成本节约、信息流通加速等直接效益可达3000万元人民币,间接效益预计可达2亿元人民币。
CIO之家 www.ciozj.com 公众号:imciow