Facebook放弃Cassandra之后,对HBase 0.89版本进行了大量稳定性优化,使它真正成为一个工业级可靠的结构化数据存储检索系统。Facebook的Puma、Titan、ODS时间序列监控系统都使用HBase作为后端数据存储系统。在国内公司的一些项目中也用到了HBase。
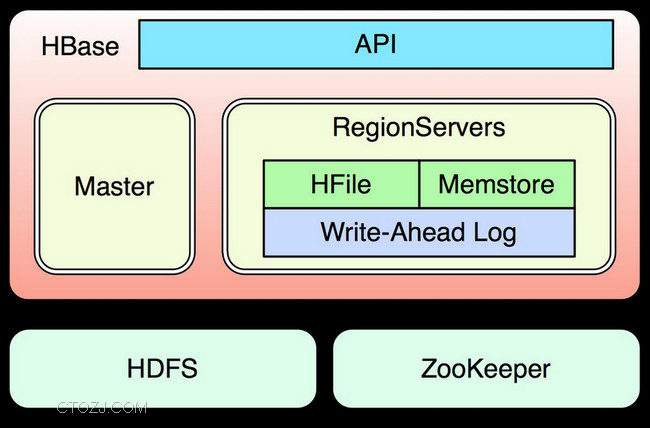
HBase隶属于Hadoop生态系统,从设计之初就十分注重系统的扩展性,对集群的动态扩展、负载均衡、容错、数据恢复等都有充分考虑。相比于传统关系型数据库,HBase更适用于数据量大、读写吞吐量非常高、对数据可靠性一致性及数据操作的事务性要求较低的应用。
HBase使用HDFS作为存储层,HDFS屏蔽了底层文件系统的异构性,集群数据的负载均衡、容错、故障恢复都对上层透明。这使得HBase的结构极为简单清晰,集群扩展性非常突出。同时HBase使用ZooKeeper作为分布式消息中间件,管理集群运行时各节点状态,保证分布式事务的一致性。
通过使用HDFS和ZooKeeper,HBase要达到管理节点Master和服务节点Region Server运行时无状态的设计理念,服务节点Region Server中管理的MemStore和BlockCache等结构的本质意义都是缓存。系统运行时随时替换、添加或删除服务节点时不需要依赖之前服务节点保存的任何信息,负载均衡、集群扩展及失效时数据恢复的处理流程都极为简单,添加服务器或发现服务器下线之后对集群负载重新均衡等操作在不需要回滚日志的情况下都能在1分钟甚至几秒钟完成。HBase中的管理节点HMaster的工作则只是维护ZooKeeper中存储的集群状态变化的时序,充当WatchDog的角色。当管理节点出现异常情况时,Backup Master可以立即激活,不影响集群的正常使用。
HBase的各种问题
HBase也有众多用户诟病的不足,例如原生HBase不支持索引(众多NoSQL数据都把索引作为自己支持的基本功能,例如也有众多拥趸的MongoDB)查询方式单一,只支持基于主键的数据读写和范围查询,对非主键列的数据筛选只能通过过滤器低效完成,如果用户从客户端建立索引,则需要自己维护索引表与数据表的一致性,同时HBase也不支持跨行或跨表事务,操作冲突导致失败时数据回滚这些复杂逻辑都需要用户自己完成。
HBase底层使用HDFS作为持久化层,由于HDFS保持副本一致性的方式非常简单,一旦文件生成便不支持数据的修改。HBase不得不使用LSMTree结构通过刷写新文件并通过同时查询多个存储文件中的内容,然后按时间戳归并结果来模拟实时修改数据。所以在经历长时间数据写入之后会生成许多存储文件,传统机械硬盘每秒随机寻道次数非常有限,且随机寻道时间都在10ms左右,远大于HBase查找block等其他读取数据时必要操作的时间,从多个存储文件中查找数据会引发读取性能尤其是随机读取性能成倍下降。
在生成多个存储文件之后,HBase为了缓解数据读取性能的下降需要定期进行数据文件归并操作Compaction。由于Compaction一般情况下需要读取一个分区的所有存储文件,并将记录排序后重新写到一个新的存储文件中。执行期间会消耗大量系统网络带宽、内存、磁盘I/O以及CPU资源,非常容易造成系统过载。一旦带宽开销过大造成网络时延或者内存开销过大引发Region Server执行长时间的GC操作时,有可能导致其长时间对外停止服务。如果停止服务的时间维持到ZooKeeper租约超时,Master会认为此服务器宕机并通知其下线,然后重新将此Region Server上承担的数据分发到其他服务器上。这个过程通常会持续2~3分钟,而最坏情况下如果同时这台Region Server上正好有Meta表,就可能导致整个集群在此期间无法对外提供服务。
此外,由于HBase底层使用列存储结构固化数据,处理非稀疏数据时会有较大的数据冗余造成数据膨胀。通常情况下,存入10列左右的数据,不计副本的膨胀率为3~5倍。想减少这种数据膨胀最为简单的办法是尽量减少行键、列簇、列的长度。最极端的情况下,我们曾经把数据都写在HBase表的RowKey中,以此减少膨胀率提高数据范围查询和随机读取的速度。这种方式将HBase退化为KeyValue存储来提升读写性能,但大多数应用还是希望数据存储结构尽量贴近应用的逻辑结构或尽量贴近关系表中表的结构,所以不得不使用Snappy等压缩算法对数据进行压缩或是采用HFile V2使用行前缀压缩来减少冗余。但这两种压方式特别是采用压缩算法后都会大幅度影响HBase随机读取的性能。压缩算法为了提高压缩效率通常需要维护一段合适的buffer,压缩时对buffer内的数据统一压缩成一个压缩块。HBase中存储文件的block默认大小为64KB,而Snappy压缩buffer为256KB,这会大大增加一次随机读取所需要处理的数据量,HBase本就不优秀的读取性能会进一步受到影响。
推荐系统介绍与特点
搜狐推荐引擎系统是从零基础的状态下逐步成型的,经过非常紧张的开发。目前已接入几亿用户的行为日志,每日资讯量在百万级,每秒约有几万条左右的用户日志被实时处理入库。在这种数据量上要求推荐请求和相关新闻请求每秒支持的访问次数在万次以上,推荐请求的响应时延控制在70ms以内。同时系统要求10秒左右完成从日志到用户模型的修正过程。
10秒左右的实时反馈成为目前系统的主要难点,为此我们需要维护几亿用户200GB的短期属性信息,同时依靠这些随用户行为实时变化的属性信息来更新用户感兴趣的文章主题,同时实时计算用户所属的兴趣小组,完成由短期兴趣主导的内容推荐和用户组协同推荐。
用户短期兴趣属性需要根据用户每次的点击浏览和下拉刷新三种操作频繁更新和修改。一旦系统收到用户的日志需要查找出对应相关资讯的所有信息,同时还要找到用户相关的属性数据,根据操作属性,对所有相关属性进行加权或减权。加权操作大致包括点击、浏览时长、划屏;减权操作则主要是推荐曝光。这些数据都要实时回写到用户库中,同时每次推荐也会直接从库中获取用户短期兴趣模型,以此捕捉到用户当前的浏览阅读兴趣。除此之外,还有一些频率较低的操作,例如记录用户浏览历史、周期性计算热门文章。这些操作都是在HBase上完成的。
系统中最为苛刻的需求是处理每秒几万条左右的用户日志,单条日志对应的资讯属性约为5到10个,同时更新属性最简单的情况需要读出用户原有对应属性然后进行加权或减权后存回属性表。因此,存储系统处理日志时对应每秒随机读写次数约为几十万次。系统还需要处理每秒万次的推荐请求,这么多推荐请求都需要读取每个用户当前最新的短期模型,同时请求的返回时间需要控制在70ms以内,这样包括磁盘随机寻道甚至数据命中磁盘、JVM GC都成为存储系统需要尽力避免的问题。
满足苛刻的随机数据读写需求
目前整个系统承担压力的核心部分就是HBase,HBase读写最为频繁的数据是用户短期属性。而原生HBase最大的问题之一就是数据随机读写速度太慢。为了满足目前应用的需求,我们基于HBase开发了一套完全利用内存的数据存储系统。下面将分两部分介绍基于内存的存储系统和HBase如何承载前端巨大的数据增删改查的压力。
MemT承担系统核心压力
由于我们代码里将HBase上的内存数据存储系统的包名叫memtable,所以这里把这套东西简称为MemT。MemT目前单集群部署了10台服务器(10对10热备)主要存储200GB用户短期兴趣和最近30天文章的摘要信息。
MemT主要功能包括单服务器每秒支持近20万次增删改查操作,支持与HBase相同的行、列簇、列的表结构,支持TTL时间戳数据管理,支持HBase中所有Filter的数据过滤。同时还封装了一些系统常用函数,例如求一行数据中列或列值TopN、按时间平滑数据和计算衰减等。
为了保证系统的可用性,MemT在单个集群中会维护两张内存表互为备份,节点宕机时客户端会自动切换到当前可用的副本上,应用一般对宕机无感。同时MemT还利用了HBase自身的负载均衡(balancer)及宕机Region恢复策略来管理自己的内存数据分片。在单个副本不可用时,客户端会快速切换到可用副本上,所以不会出现HBase RS宕机时等待session超期的情况。宕机后停止服务的节点上所有数据会被分配到集群其他服务器上,收到新数据分片的服务器开始加载数据到内存中同时对外提供服务。集群内存中的各个备份之间通过HBase中一张日志表同步数据,客户端可以选择把数据写到日志表中,也可以强制刷写MemT各服务端的内存来同步数据。日志表被Hash为40个Region分布在集群中,某个服务器宕机之后,其数据也会被均分到集群的其他服务器上,由整个集群来恢复宕机服务器内存中的数据,所以数据恢复的速度非常快,恢复完近期日志中的数据后还需要恢复dump表中的内容。这个过程后面详细介绍。目前线上集群挂掉一台Server,从日志检查到恢复内存约20GB数据的时间不到1分钟。
当内存中数据增长超过用户配置的阈值时(目前是25GB),系统会按Region大小排序后,从最大的Region开始按LRU规则把内存中的数据淘汰到对应HBase的dump表中,同时在内存里将该行dump标记置为true。当系统再次读取该行时,dump表里对应的内容会再次被加载到内存中按时间戳归并结果,同时修改dump标记为false。如果dump标志位为true,系统更新此行内的数据也会被直接放到dump表中来节约内存。dump表对应的HBase Region和MemT对应的数据分片会被分配到同一台服务器上,来保证其交互时的性能。
系统日志表里的内容标记为6个小时过期,同时每4个小时系统会将内存中的数据做一份快照。快照流程与内存不足时将数据存放到dump表中的流程相似。不同的是快照不影响每行数据的dump标志位,当内存分片完成快照之后,恢复数据时快照之前的日志就可以丢弃并直接从快照中恢复数据。
另外,系统要求每次推荐请求相应时延在70ms。为了让MemT在每秒上万次请求时不产生大量内存碎片而频繁GC,我们重新改写了HBase的RPC层,为其中Connection、Handler这些处理RPC并主要申请内存的类设计了缓存,当RPC请求及返回数据大小在一定时间内波动范围保持不变时,Connection和Handler几乎可以重用全部处理完废弃的数据结构,以此来消除内存垃圾的产生。我们曾经一度废弃RPC Reader这一角色,所有请求都由Handler接收处理并直接返回。这样内存占用处理的通量都会有所优化。不过缺少请求队列之后请求的前后关系无法保证,无法保证先到先服务,客户端会随机出现服务时延异常高的请求。
使用HBase的情况
HBase使用原则如下。
1. 规避事务类应用。HBase默认只保证多用户单行数据操作的数据时序和一致性。如果用户需要跨行甚至跨表事务支持则需要在客户端同时拥有多行数据的锁。当HBase支持高并发数据访问时,极可能由于客户端各种问题造成死锁同时影响数据访问。如果用户需要对表段甚至表进行加锁则需要通过Coprocessor或改动Region Server代码在服务端处理加锁请求。这样的操作十分危险,可能导致整个集群所有RS的Handler线程由于循环等待而耗尽,进而使全集群对外停止服务。
目前基于HBase处理事务代价最小的方式是,数据版本通过不同操作申请不同的事务ID,同时读取数据时过滤未完成事务的数据版本来实现。总之,基于HBase处理事务类或强数据一致类的应用有些南辕北辙,违背HBase高扩展大并发高通量数据存取的设计理念。
如果应用对事务要求较高,那么可以选用传统关系数据库或新兴的一系列NewSQL数据库。例如,内存数据库VoltDB,其使用处理线程与CPU及数据分片绑定的方式,所有数据修改操作先发送到多个副本中的主副本上,由主副本管理线程统一确定顺序再由各个副本分别执行操作。使通常需要多次加锁解锁的事务操作可以在完全无锁的状态下完成。同时实测的每秒事务处理量也远超一般关系型数据库,是OLTP类应用不错的选择。
2. 避免长时间大量数据写入,同时均衡集群负载。由于HBase需要通过Compaction操作来合并写入的数据来优化数据读取性能,而Compaction操作十分消耗系统资源。为了使系统能稳定提供服务,最好手动控制数据表Compaction的时间,同时减少写入数据量来减少系统的I/O资源消耗,用户可以打开HFile的前缀压缩并且缩短行、列簇及列的长度,同时合理设计表主键将写入数据分散到所有服务器来缓解压力。同时停止系统自动,挑选低压时段,定时滚动触发。最后用户最好关闭HBase的split功能,同时在定义数据表时就预先划分数据分片,这样一方面可以避免新表由于分片数少,初期读写通量都较低的情况,另一方面可以避免split带来的多种问题。最后用户最好自己实现balance功能,例如按表粒度的balance,这样能使负载更快地分散到整个集群中。
3. 保证Meta表可用性。HBase中所有用户表的Region都依赖Meta表来确定其当前位置,Meta表的可用性关系到整个集群能否正常对外提供服务。为保证Meta表可用,我们定期将Meta表移动到集群负载最轻、内存消耗最小的服务器上。同时移动Meta表会将最新修改刷写到文件系统,防止Meta出现数据丢失。
4. 减轻ZooKeeper节点压力。HBase所有服务节点及数据分片调度操作时序、所有服务节点的生存期Session以及客户端查询服务节点地址等操作都是由ZooKeeper完成的。ZooKeeper节点之间也需要全量同步所有数据,因此降低节点负载、保证网络可达非常重要。通常在服务器资源充足的情况下,建议将Master、Backup Master和ZooKeeper节点部署在一起。同时不在节点上运行Region Server等资源消耗较多的进程。
5. 避免随机读取,利用缓存减少热数据延时。目前推荐系统内读取、更改最频繁实时要求最高的用户数据短期兴趣数据被放到了MemT中,但还有一些数据量更大,但更新和修改并没有那么频繁的数据被存储在HBase中。例如,所有新闻资讯的原始数据,所有用户的长期兴趣模型等,这些数据基本入库之后就不会更新,同时前端推荐服务器读取一遍数据基本就可以把较热的部分数据缓存本地并很长时间不需要再次访问HBase,这些数据加速方式基本就是各应用使用本地Cache。
6. 防止Region Server假死。通常情况下,Region Server进程由于GC或其他原因假死或退出时,ZooKeeper中维持的Session会超期,并由此引发Master的数据恢复流程。但极少数情况下,我们也遇到Region Server无法对外提供服务但Session并不超期的情况,这种情况会造成一部分数据一直无法访问。为了避免这种情况分生,我们的系统监控进程会定期读取每片Region的首行数据,在多次无返回或者超时的情况下调用脚本重启Region Server,快速发现服务节点异常,快速下线重新分配数据。此外,由于Region Server因为GC发生宕机的情况非常常见,我们会定时重启所有服务,使下线的Region Server重新启动,同时均衡集群负载。
前面介绍了很多使用HBase需要注意的问题,其实实际使用中HBase大多数时间还是非常稳定并且有不错的性能。HBase上顺序Scan和数据写入速度都能达到上万次每秒。目前系统中还有很多类似数据仓库存储过程的数据整理操作,由于涉及的数据量比较大也被放到HBase上执行,例如各个源之间数据结构的转换、日志数据用户数据资讯数据的拼接以及文章热度发布量的计算等。这些操作大多都是利用HBase顺序读写,虽然处理的数据量稍大,但也没有对线上系统造成过度的压力。将这些操作直接在HBase上执行,简化了系统整体的复杂程度。
总之,HBase能够利用大量廉价的PC Server提供非常出色的高并发且大流量的数据读写性能。即便不做细粒度的优化,简单增加服务器数量也能成倍提高读写通量增加系统的处理能力和稳定性。
系统的其他模块
目前系统其他模块还包括用作传递日志和其他消息的Kafka队列,离线计算用户模型的Hive、Pig、Mahout,和其他一些运维管控系统。Kafka消息队列的读写性能非常优秀,但会出现消息乱序以及消息重复发布的情况。系统目前所有统计指标数据都是通过Hive处理日志得出的。Hive的开发难度很低易于使用并且产量很高。Pig主要用于初期日志清洗,Mahout则用于用户模型计算等方面。
结束语
内容推荐引擎系统集成了重多开源系统,是站在巨人的肩膀上摘到当前的成果。
对比其他NoSQL系统(例如Redis、MongoDB、Cassandra等),HBase基于HDFS不支持复杂事务、最初设计中最大的考量因素就是扩展性,其设计的初衷就是基于集群、扩展性好、故障恢复机制清晰高效、基于水平分片的负载分发模式易于调整。
这些降低了我们设计系统的难度,良好的扩展性让我们不必担心由于系统用户量倍增长,不得不自己处理数据分片、调度、同步、可靠性等一系列问题。集群规模随用户规模同步线性扩展是最廉价的升组系统的方式。
同时HBase简单清晰的代码结构也让我们解决其各种问题或定制化二次开发成为可能。HBase中众多功能强大的组件,例如Bloom过滤器HFile和RPC等,也被拆解出来重新用于其他系统的开发。目前系统中的HBase以及基于HBase的一系列衍生系统已可以胜任大部分苛刻的需求,并且长期在低负荷稳定状态下对外提供服务。
作者刘佳,曾参与过淘宝数据魔方的改造,腾讯广点通的系统升级等项目。目前于搜狐移动研发部负责移动内容推荐引擎系统的建设。
CIO之家 www.ciozj.com 公众号:imciow