Hadoop业界正在迅速发展,从业企业拿出的解决方案也多种多样,其中包括提供技术支持、在托管集群中提供按时租用服务、为这套开源核心开发先进的功能强化或者将自有工具添加到方案组合当中。
在今天的文章中,我们将一同了解当下Hadoop生态系统当中那些最为突出的杰作。总体而言,这是一套由众多工具及代码构成的坚实基础、共同聚集在"Hadoop"这面象征着希望的大旗之下。
Hadoop

虽然很多人会把映射与规约工具广义化称为Hadoop,但从客观角度讲、其实只有一小部分核心代码算是真正的Hadoop。多个工作节点负责对保存在本地的数据进行功能执行,而基于Java的代码则对其加以同步。这些工作节点得到的结果随后经过汇总并整理为报告。第一个步骤被称为"映射(即map)",而第二步骤则被称为"规约(reduce)"。
Hadoop为本地数据存储与同步系统提供一套简化抽象机制,从而保证程序员能够将注意力集中在编写代码以实现数据分析工作上,其它工作交给Hadoop处理即可。Hadoop会将任务加以拆分并设计执行规程。错误或者故障在意料之中,Hadoop的设计初衷就在于适应由单独设备所引发的错误。
项目代码遵循Apache许可机制。
官方网站:hadoop.apache.org
Ambari

Hadoop集群的建立需要涉及大量重复性工作。Ambari提供一套基于Web的图形用户界面并配备引导脚本,能够利用大部分标准化组件实现集群设置。在大家采纳Ambari并将其付诸运行之后,它将帮助各位完成配置、管理以及监管等重要的Hadoop集群相关任务。上图显示的就是集群启动后Ambari所显示的信息屏幕。
Ambari属于Apache旗下的衍生项目,并由Hortonworks公司负责提供支持。
下载地址:http://incubator.apache.org/ambari/
HDFS (即Hadoop分布式文件系统)

Hadoop分布式文件系统提供一套基础框架,专门用于拆分收集自不同节点之间的数据,并利用复制手段在节点故障时实现数据恢复。大型文件会被拆分成数据块,而多个节点能够保留来自同一个文件的所有数据块。上图来自Apache公布的说明文档,旨在展示数据块如何分布至各个节点当中。
这套文件系统的设计目的在于同时实现高容错性与高数据吞吐能力的结合。加载数据块能够保持稳定的信息流通,而低频率缓存处理则将延迟降至最小。默认模式假设的是需要处理大量本地存储数据的长时间作业,这也吻合该项目所提出的"计算能力迁移比数据迁移成本更低"的座右铭。
HDFS同样遵循Apache许可。
官方网站:hadoop.apache.org
HBase

当数据被汇总成一套规模庞大的列表时,HBase将负责对其进行保存、搜索并自动在不同节点之间共享该列表,从而保证MapReduce作业能够以本地方式运行。即使列表中容纳的数据行数量高达数十亿,该作业的本地版本仍然能够对其进行查询。
该代码并不能提供其它全功能数据库所遵循的ACID保证,但它仍然为我们带来一部分关于本地变更的承诺。所有衍生版本的命运也都维系在一起--要么共同成功、要么一起失败。
这套系统通常被与谷歌的BigTable相提并论,上图所示为来自HareDB(一套专为HBase打造的图形用户界面客户端)的截图。
Hive
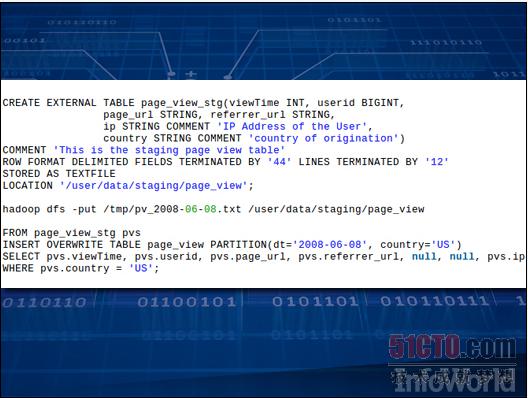
将数据导入集群还只是大数据分析的第一步。接下来我们需要提取HBase中来自文件的所有数据内容,而Hive的设计初衷在于规范这一提取流程。它提供一套SQL类语言,用于深入发掘文件内容并提取出代码所需要的数据片段。这样一来,所有结果数据就将具备标准化格式,而Hive则将其转化为可直接用于查询的存储内容。
上图所示为Hive代码,这部分代码的作用在于创建一套列表、向其中添加数据并选择信息。
Hive由Apache项目负责发行。
官方网站:hive.apache.org
Sqoop
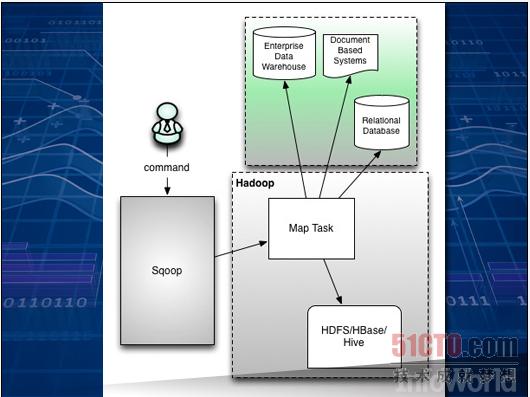
要将蕴藏在SQL数据库中的数据宝库发掘出来并交给Hadoop打理需要进行一系列调整与操作。Sqoop负责将饱含信息的大型列表从传统数据库中移动到Hive或者HBase等工具的控制之下。
Sqoop是一款命令行工具,能够控制列表与数据存储层之间的映射关系,并将列表转化为可为HDFS、HBase或者Hive所接纳的可配置组合。上图所示为Apache文档材料中的内容,可以看到Sqoop位于传统库与节点上的Hadoop结构之间。
Sqoop的最新稳定版本为1.4.4,但目前其2.0版本同样进展顺利。两个版本目前都可供下载,且遵循Apache许可。
官方网站:sqoop.apache.org
Pig
一旦数据以Hadoop能够识别的方式被保存在节点当中,有趣的分析工作将由此展开。Apache的Pig会用自己的小"猪拱"梳理数据,运行利用自有语言(名为Pig Latin)所编写的代码,并添加处理数据所需要的各种抽象机制。这样的结构会一步步指引用户走向那些易于以并行方式运行在整个集群当中的算法。
Pig还拥有一系列针对常见任务的标准化功能,能够轻松处理诸如数据平均值计算、日期处理或者字符串差异比较等工作。如果这些还不够用--实际上一般都不够用--大家还可以动手编写属于自己的功能。上图所示为Apache说明文档中的一项实例,解释了用户如何将自己的代码与Pig代码结合起来、从而实现数据发掘。
目前Pig的最新版本为0.12.0。
官方网站:pig.apache.org
ZooKeeper
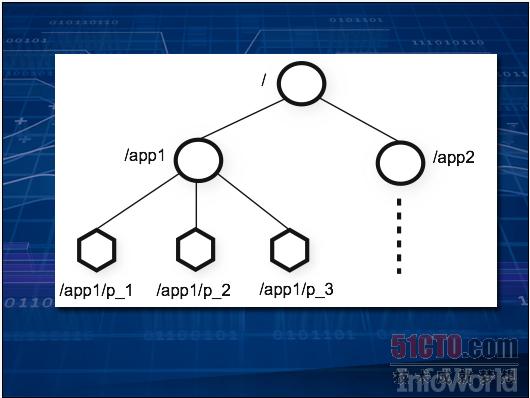
一旦Hadoop需要在大量设备之上,集群运作的顺序就显得非常重要,特别是在其中某些设备开始签出的情况下。
ZooKeeper在集群中强制执行一套文件系统式的层级结构,并为设备保存所有元数据,这样我们就可以在不同设备之间进行作业同步。(上图所示为一套简单的二层式集群。)说明文档展示了如何在数据处理流程中实施多种标准化技术,例如生产方-消费方队列,从而保证数据能够以正确的顺序进行拆分、清理、筛选以及分类。当上述过程结束后,使用ZooKeeper的节点会彼此通信、并以最终生成的数据为起点开始分析工作。
如果大家希望了解更多信息、说明文档以及最新版本,请访问ZooKeeper的官方网站。
官方网站:zookeeper.apache.org
NoSQL
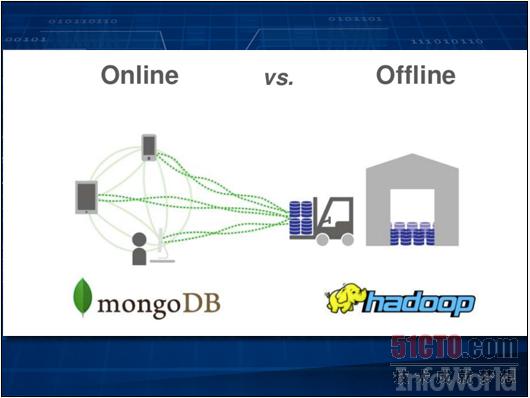
并不是所有Hadoop集群都会使用HBase或者HDFS。某些集成了NoSQL的数据存储体系会采取自己的独特机制实现跨集群各节点的数据存储任务。在这种情况下,此类体系能够利用NoSQL数据库的全部功能对数据进行存储与检索,而后利用Hadoop规划同一集群当中的数据分析作业。
此类方案中最为常见的当数Cassandra、Riak或者MongoDB,而用户则在积极探索将这两种技术加以结合的最佳方式。作为MongoDB的主要支持厂商之一,10Gen公司建议用户利用Hadoop进行离线分析,而MongoDB同时仍然能够以实时方式统计来自Web的数据。上图所示为连接器如何实现两套体系之间的数据迁移。
Mahout
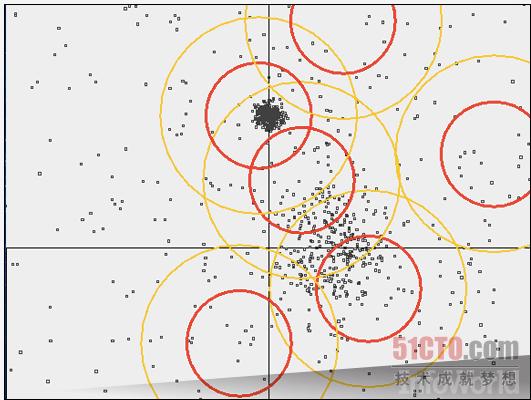
目前能够帮助我们进行数据分析、分类以及筛选的算法多种多样,而Mahout项目的设计目的正是为了将这些算法引入Hadoop集群当中。大多数标准化算法,例如K-Means、Dirichelet、并行模式以及贝叶斯分类等,都能够让我们的数据同Hadoop类型的映射与规约机制进行协作。
上图所示为一套篷聚类集群化算法,它选择点与半径来构成圆圈、从而覆盖整个点集合中的对应部分。这只是众多Hadoop内置数据分析工具之一。
Mahout从属于Apache项目并遵循Apache许可。
官方网站:mahout.apache.org
Lucene/Solr
这是目前惟一的一款用于检索非结构化文本大型块的工具,它同时也是Hadoop的天生合作伙伴。由于利用Java编写,Lucene能够轻松与Hadoop展开协作,共同创建出一套用于分布式文本管理的大型工具。Lucene负责处理检查任务、Hadoop则负责将查询分布到整个集群当中。
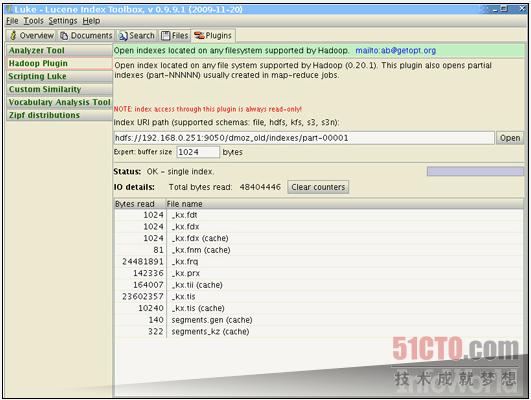
新的Lucene-Hadoop功能正迅速发展成为全新项目。以Katta为例,作为Lucene的衍生版本,它能自动对整个集群进行解析。Solr则提供集成度更高的动态集群化解决方案,能够解析XML等标准化文件格式。上图所示为Luke,一款用于Lucene浏览的图形用户界面。它现在还提供插件、用于对Hadoop集群进行浏览检索。
Lucene及其多个衍生版本都属于Apache项目的组成部分。
官方网站:www.apache.org
Avro

当Hadoop作业需要进行数据共享时,我们完全可以使用任何一种数据库加以实现。但Avro是一套序列化系统,能够利用一定模式将数据整理起来并加以理解。每一个数据包都附带一种JSON数据结构,用于解释数据的具体解析方式。这种数据头会指定数据结构,从而避免我们在数据中编写额外的标签来对字段进行标记。如此一来,当共享数据较为规律时,其体积将比传统格式(例如XML或者JSON)更为紧凑。
上图所示为针对某个文件的Avro处理模式,其中分为三种不同字段:姓名、最喜欢的数字与最喜欢的颜色。
Avro同样属于Apache项目的组成部分,其代码拥有Java、C++以及Python等多个语言版本。
官方网站:avro.apache.org
Oozie
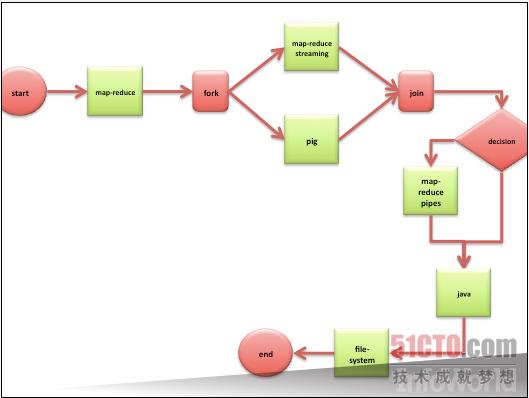
将一项作业拆分成多个步骤能够让工作变得更为简单。如果大家将自己的项目拆分成数个Hadoop作业,那么Oozie能够以正确的顺序将其组合起来并加以执行。大家不需要插手堆栈调整,等待一个堆栈执行结束后再启动另一个。Oozie能够按照DAG(即有向无环图)的规范对工作流加以管理。(环图相当于无限循环,对于计算机来说就像一种陷阱。)只需将DAG交给Oozie,我们就可以放心出去吃饭了。
上图所示为来自Oozie说明文档的一幅流程图。Oozie代码受到Apache许可的保护。
官方网站:oozie.apache.org
GIS工具
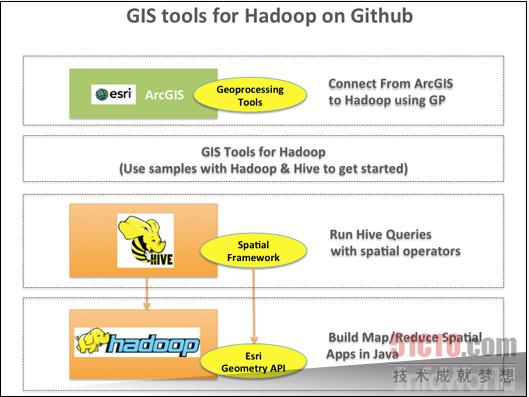
咱们生活的世界相当广阔,因此让运行Hadoop的集群与地理地图协作也是项难度很高的任务。针对Hadoop项目的GIS(即地理信息系统)工具采用多种基于Java的最佳工具,能够透彻理解地理信息并使其与Hadoop共同运行。我们的数据库将通过坐标而非字符串来处理地理查询,我们的代码则通过部署GIS工具来计算三维空间。有了GIS工具的帮助,大家面临的最大难题只剩下正确解读"map"这个词--它到底代表的是象征整个世界的平面图形,还是Hadoop作业当中的第一步、也就是"映射"?
上图所示为说明文档中关于这些工具的不同层级。目前这些工具可在GitHub上进行下载。
下载地址:http://esri.github.io/gis-tools-for-hadoop/
Flume
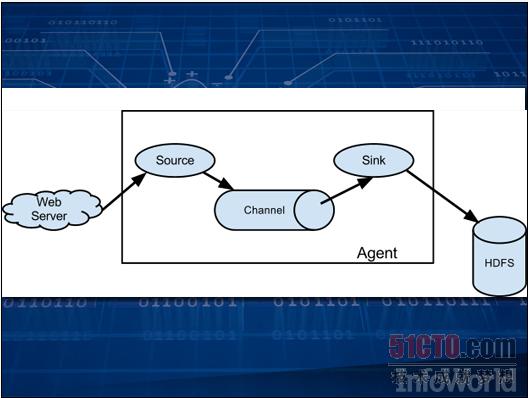
数据收集这项任务绝对不比数据存储或者数据分析更轻松。作为又一个Apache项目,Flume能够通过分派"代理"以收集信息并将结果保存在HDFS当中。每一个代理可以收集日志文件、调用Twitter API或者提取网站数据。这些代理由事件触发,而且可以被链接在一起。由此获得的数据随后即可供分析使用。
Flume项目的代码受Apache许可保护。
官方网站:flume.apache.org
Hadoop上的SQL
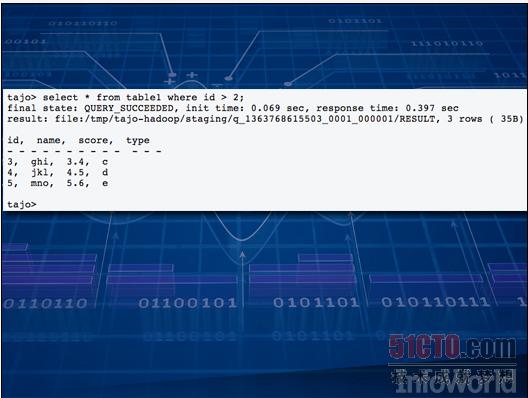
如果大家希望在自己的大型集群当中对全部数据来一次快速的临时性查询,正常来说需要编写一个新的Hadoop作业,这自然要花上一些时间。过去程序员们多次掉进过这同一个坑里,于是大家开始怀念老式SQL数据库--利用相对简单的SQL语言,我们就能为问题找到答案。从这一思路出发,众多公司开发出一系列新兴工具,这些方案全部指向更为快捷的应答途径。
其中最引人注目的方案包括:HAWQ、Impalla、Drill、Stinger以及Tajo。此类方案数量众多,足够另开一个全新专题。
云计算

很多云平台都在努力吸引Hadoop作业,这是因为其按分钟计算租金的灵活业务模式非常适合Hadoop的实际需求。企业可以在短时间内动用数千台设备进行大数据处理,而不必再像过去那样永久性购入机架、再花上几天或者几周时间执行同样的计算任务。某些企业,例如Amazon,正在通过将JAR文件引入软件规程添加新的抽象层。一切其它设置与调度工作都可由云平台自行完成。
上图所示为Martin Abegglen在Flickr上发表的几台刀片计算机。
Spark
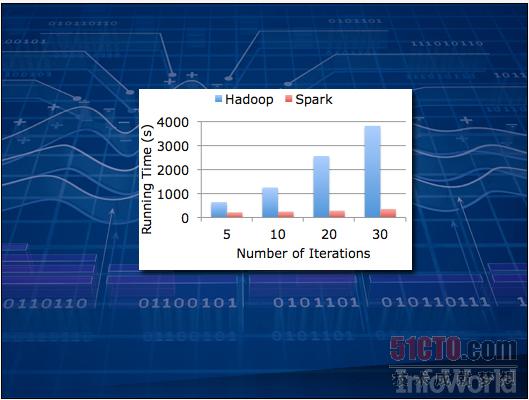
未来已然到来。对于某些算法,Hadoop的处理速度可能慢得令人抓狂--这是因为它通常依赖于存储在磁盘上的数据。对于日志文件这种只需读取一次的处理任务来说,速度慢些似乎还可以忍受;但一旦把范围扩大到所有负载,那些需要一次又一次访问数据的人工智能类程序可能因为速度过慢而根本不具备实用价值。
Spark代表着下一代解决思路。它与Hadoop的工作原理相似,但面向的却是保存在内存缓存中的数据。上图来自Apache说明文档,其中演示的是Spark在理想状态下与Hadoop之间的处理速度对比。
Spark项目正处于Apache开发当中。
官方网站:spark.incubator.apache.org
原文链接:http://www.infoworld.com/slideshow/131105/18-essential-hadoop-tools-crunching-big-data-232123#slide1
CIO之家 www.ciozj.com 公众号:imciow