我去了一趟美国,看到大数据领域的几个变化,这些变化有可能极大地改变世界。
第一个变化是开始从被动搜集数据,转变为主动搜集数据。
美国一家公司现场给我们表演,电视里正在播放新闻,他们把手机放在电视机旁,手机很快识别出这是CNN新闻频道,以及正在播出什么内容。我们三个人拿出自己的手机,手机同时放三首不同的歌,他们的软件很快辨别出这三首歌是什么,以及作为背景正在播放的电视新闻。这意味着,非结构性的数据编程结构性数据,开始从被动搜集数据转变为主动搜集数据。
第二个变化是非实时转实时。
滴滴打车的数据可以说明不同地点的人流情况,但是零售业得到了这些数据,又如何触到它的用户群呢?大家知道这个世界有一个,DSP(Demand-Side Platform 需求方平台),作为中间方,DMP记录用户去了哪个网站,用了什么APP。当人使用APP时,数据会告诉DSP,这个人出现在了某一个地方,DSP就能够帮商户做智能投放。由于背后有大数据支撑,投放在很短的时间内就能完成。这种模式对营销来说,绝对是一个颠覆。
还有一个非常重要的变化是对话。
美国有两大公司,几乎同时宣布了一项战略性科技——对话的人工智能。比如,你的房间有一个音响,这个音响同时是一个传感器。当你说“我要买一瓶酱油”,音响会和你说:“老板,你是不是要买你之前买过的酱油?”你说:“不是,我要买新的。”它就会告诉你,新的酱油以及同样差不多的有几种,建议你选择哪种。这个变化将引发一个大的颠覆。
隐私+归属权:从混沌走向清晰
说到大数据,不得不提的是大数据与隐私这个问题。
这次在美国,我见到了一位在隐私问题上给美国总统提意见的专家。他说,关于个人隐私会有一个颠覆性的变化,这一变化在欧洲已经开始了,现在是美国。过去,当用户使用一个应用时,都会和应用方签订一个协议,表明用户同意把自己的数据交给应用方以改善用户体验。但是,大部分人都不知道自己同意的是什么,仅仅是点击了“同意”。美国的法律对此准备进行修改,这可能会改变大数据产业。
在这个变化中有个问题,数据分可识别数据、不可识别数据。互联网上的数据,有的可以识别是你,有的不可以识别是你。当不能完全知道他是谁,没有办法和他说你是否同意时该怎么办?现在,美国正在认真讨论类似的事情。
另一个问题是数据的拥有权是谁?早期大家是按照实物的思路,来定义数据拥有权的法律,后来发现这条路撞墙了。数据的可爱之处就是看见就看见了,不在于是你拿着还是我拿着。法律界已经开始关注这个问题。
关于隐私问题,大部分用户更多是希望平衡好,你不能拿到我的数据我一点好处都没有,你拿了数据使用我却一点都不知道。所以,问题是谁有权控制?比如脸书,每一次使用用户数据,会告诉用户,这个数据会在某个点使用,这就涉及数据使用透明和是否可控的权利问题。这个行业里面很多人不想讲这个问题,但并不是不知道。这是我们做大数据的人必须要慢慢解决的,否则这是一个定时炸弹。
当然,有大量的数据不相关隐私。比如,用1000个人或者5000个人的数据算出来的结果,当做大数据营销的时候,有没有把他捆绑在5000个人当中营销?美国有些法案很可爱,认定个人数据的隐私问题不是放在单独的案例当中,而是放在行业里面。我问专家,为什么要放在行业里面?他说,个人隐私和行业有关,比如卖药的,个人隐私的监管就会非常严格,而游戏类的个人数据会相对简单一些。在欧洲则是一套法律,不分行业。欧洲人认为,隐私是一个人的底线。而美国认为价值和隐私之间可平衡。这些都是未来大家都会议论的课题。
做好缝合,不断迭代
大数据的本身是异构异类的数据,就像裁缝把不同的材料缝成一件衣服一样,需要很多技术把数据连接起来,让这些数据可以使用。不同材料缝合在一起,中间会有一些缝合处。
美国任何一个做大数据的人,都会告诉你数据关联很难。美国可以把数据关联起来的公司有几家。美国大数据行业在产业链上,是可以分工的。你干这个,我干那个,大家协同把东西做出来。这和中国的情况是有区别的。
要把大数据整合起来,数据源好不好非常重要。另外有没有不同的环境可以进行数据测试,也很重要。
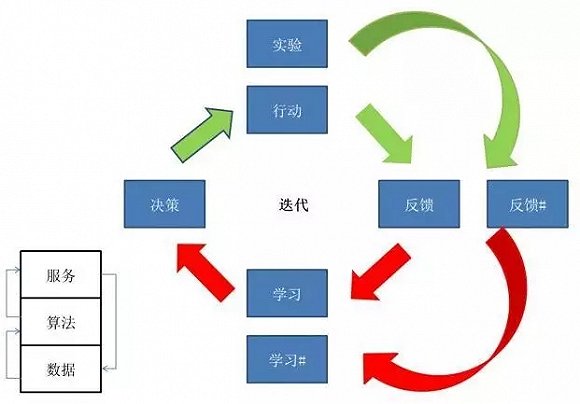
数据是迭代的,算法是迭代的,产品服务也是迭代的。数据有不同的版本、算法有不同的版本,我们要找到最优、同一个语境下最好的算法,达到最好的服务。
将大数据变成企业的洞察力和行动力
对于企业来说,需要将大数据变成企业的洞察力、行动力。10年前,商业决策都是靠经验驱动,用数据证明自己的判断是对的。而数据驱动,则要拥有足够的数据,通过数据发现一些以前没有看到的东西。
比如,有一些人在购物网站搜索过的关键词,两个月后会成为比较流行的关键词。当我们深入分析时,数据会告诉我们,购物里面是有达人的,购物达人看的东西和普通人不一样,他们有自己的方法寻找自己想要的商品。如果能跟踪这些达人,就可以找到用一般推荐引擎无法找到的东西。
一个学习的完整体系,简单来讲,首先有目标定义,之后进行决策、行动、拿到行动结果之后学习。人类学习的一般方法,都是根据这个链路进行,这叫“自学习”:用自己的经验慢慢积累,进行一个自我循环。
当我们开始做大数据的时候,你会发现,别人的数据会成为你的经验。你也可以把别人的数据代入自己的决策,学习到别人的经验,这叫“集体智慧”。在大数据当中,我们可以找到别人的集体智慧。
大数据里的创新,可以有三个层面:数据的创新、算法的创新、服务的创新。
下面这张图中有四个坐标:数据集中、数据分散、问题清楚、问题不清楚。过去我们可以解决的是数据集中、问题很清楚的部分,后来开始出现很多碎片化、分散的数据,我们发现可以用零散的、没有集合、没有结构化的数据,更好地解决原来的问题。
举一个例子,有一个网站虽然有几亿用户群,但只有几百万人买彩票。如何找到更多用户到这个网站上买彩票呢?按以往的方法,先描述买彩票的人是什么样的,经验认为男的比较喜欢买彩票,年纪应该是25-35岁。而用大数据的方法,则是想猜用户下一步想做什么,可以看4周之内用户有没有看过彩票的内容,如果有,那他就是一个希望要买彩票的人,只是没有在网站里买。用这个思路,我们发现买彩票的女性比男性多,而且往往是在办公室里买的多。这样一来,数据就指明了哪些人在哪些地点是最好去做营销的。
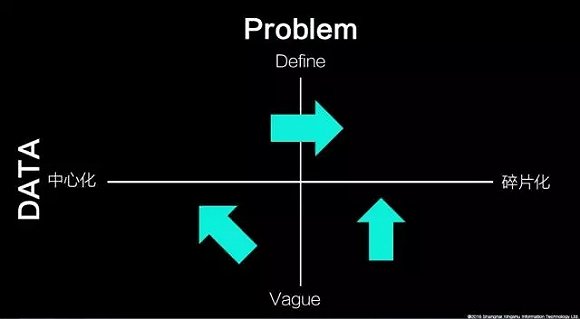
对于数据零散且问题不是很清楚,大数据同样可以解决。比如在面对不知道客户是什么样的人,只知道这些人是重复购买的人,而想要用大众标签去描述这些人时,可以先猜1000个人,对他们进行营销,发现有些人被猜对,有些人被猜错。对猜对的那部分人继续深入,慢慢就会越做越准确。这就是我通常讲的“用数据养数据”。
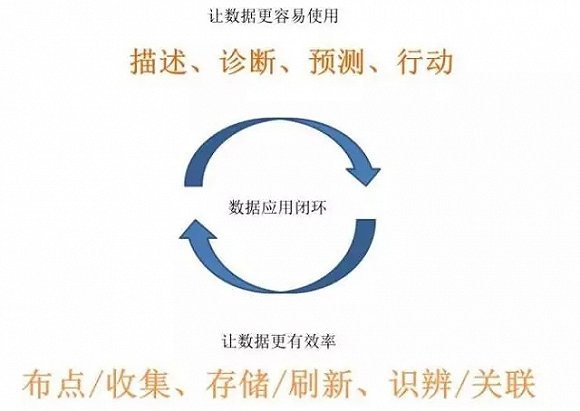
一个公司有没有大数据能力,一般看他有没有预测能力和行动能力。但是布点/收集、存储/刷新、识辨/关联,也很重要。前者是如何让数据更容易使用,后者是如何让数据更有效关联在一起。这个闭环如果可以做好,就可以做一个非常好的数据产品。
考量“好数据”的六把标尺
好的数据,六个衡量标准是缺一不可。缺少其中任何一个,数据质量就会下降。有的数据很稀缺,很独家,那就是数据价值。数据质量,主要要看准不准,但还要看全不全。如果你只拿到安卓的数据,没有拿到苹果的数据,那就不全。一段段很零散的数据买过来,没有连续性的数据也是不行的。需要找很可靠的伙伴来提供算法、数据、服务。
一家公司是否能用好自己的数据,首先要看一个公司高管、员工有没有意愿,接着看工具。有意愿、有能力、有工具的前提下,才谈到整个公司一定要对数据有自己的方向,有组织保障,以及执行到位。
信息数据化的研究,还应该包括应用无线化。对话性的产品,将是颠覆世界的产品。互动的产品,将来或许会越来越多,这也是我们在创新产品时非常大的机会。
(作者为红杉资本中国基金会专家合伙人、原阿里数据委员会会长。)
CIO之家 www.ciozj.com 公众号:imciow