随着今日头条估值80亿美元的新闻传出,“个性化推荐”这个词又成为了广受科技界和资本市场追捧的热点。一时间“个性化推荐”伴随着“大数据”、“深度学习”等高大上的词汇,让人觉得非常高深莫测。尤其是对于不懂技术的产品经理,面对诸如"特征降维"、“置信区间”、“潜在因子矩阵”这样的术语,早已云里雾里了。那么对于一个普通的产品经理而言(非数据挖掘型PM),最少需要掌握哪些和算法相关的知识呢?于是我决定写一篇针对PM的算法科普文。
1 接入算法前的准备
1.1 什么是推荐算法
首先我们需要对推荐算法有所了解,知道它的历史和简介
- 20世纪90年代中期,Amazon的推荐应用使推荐学术研究开始热起来,CF(协同过滤)方法是最先被应用认可的方法;
- 2006年,Netflix举办的推荐引擎优化大赛,100万美元的大奖,使得推荐系统再次引起学术界和工业界的关注,MF(矩阵分解)及混合模型成为推荐系统领域关注的热点;
- 移动互联网、大数据时代来临,推荐系统也发生很大的改变。从本质上说,推荐系统要解决的问题,就是在产品中,在合适的时刻,通过合适的渠道,把合适的内容推荐给合适的人,以解决信息过载问题,是联系物品和用户的中介系统。
1.2推荐算法是万能的吗?
个性化算法只是推荐系统的一部分,一个完整的推荐系统体系还应包括官方团队推荐(Editorial)、UGC(User-Generated Content)和热门推荐(Top Seller/Trending)等
个性化推荐算法不是万能的,以推荐算法最基本的CF(基于行为的协同过滤)和Item-based Similarity(基于内容相似性)为例子,前者需要用户的行为数据,后者需要歌曲的元数据(metadata),比如旋律、Tag等等。这就意味着首先它需要大量优质的数据,所谓“大量”就是指产品中每日产生的行为数据很多,并且得到有效搜集;所谓“优质”就是指所有被推荐的item要有完善准确的特征、分类、标签等(这就是为什么商品、新闻的推荐特别好做的原因,因为它们同时符合这2点)
对于很多出于发展初期或者急速扩展期的产品而言,数据肯定不够干净也不够多。这时候固然可以点归一化(Normalization),或者尝试去做Hybrid、fused的系统,尝试各种数学方式去解决问题,但是往往成本很大,而且效果一般。或者即使你的数据OK,推荐系统也很容易遇到一个越使用、推荐口味越窄的恶性循环
此外,算法根据使用者所表现出来的“兴趣”进行分类和推荐信息,往往容易给用户推荐一些低质量但用户短期内喜欢的信息。这一点在“今日头条”等新闻推荐类软件中表现最为突出。
同时,算法是无法拥有自己特有的风格的,它只会为用户推荐用户感兴趣的内容。风格是原创,是观点碰撞,是议程设置,是话语创新。算法还没学会这些,因为设计算法的技术人可能还不太懂这些。
所以这时候完全可以跳出思维,通过trending(趋势)、hot(热门)、UGC(歌单)甚至PGC(编辑推荐)的方式做推荐。这时候你可能会发现这些看似简单的方案可能会拥有比高深的个性化推荐算法更好的效果。而且,随着用户多了,用户保持engaging,老用户们持续产生高质量的数据,我们之前的个性化推荐算法也能有更好数据来调整参数,从而产生更好的推荐,更好的用户群体也能推动热门榜单与UGC的发展,进入良性循环。
1.3 你的产品是否需要个性化推荐?
根据上述解释,我们可以看到适合个性化推荐的产品需要满足以下几点:数据量足够大,用户、内容互相之间存在足够多的差异性;产品对于内容分发有较高的要求;不需要强调自己的风格或者服务特定目标人群。所以刚起步阶段的产品、某个垂直领域下的社区、工具型产品、以编辑推荐为卖点的新闻资讯软件等等,都没有太大必要接入个性化推荐算法。
1.4 如何接入个性化推荐算法?
一般来说,大产品都有独立的数据挖掘部门单独为其定制数据挖掘和个性化推荐系统,因为一套完整可用的推荐系统制作和维护成本巨大,一般的小产品和小公司是负担不起的,这时候可以选择接入第三方通用推荐系统,虽然效果没有定制的好,但是不失为一套性价比很高的方案。也可以找外面的创业公司或者独立团队外包定制一套方案,效果介于上述两者之间。
1.5 普通的产品经理需要了解算法到何种程度
这个问题就类似于“产品经理需要懂编程吗”,回答就是如果懂当然最好,但是一般情况下只要了解一些基本业务常识,可以正常和算法工程师沟通就OK了。PM更重要的事情应该是挖掘需求(用户在何时需要何种推荐),以及协调算法工程师和程序员之间的业务配合。具体落实到PM们需要了解什么又不需要了解什么,我在文章的第二部门详细描述。
2 产品经理在业务中需要懂得哪些基本知识
2.1 结合产品和运营需求确定业务需求
即从用户需求出发产生的产品需求和运营需求,产品需求即在特定页面或者时机为用户进行推荐的需求,例如当用户产生关注行为时为其推荐更多相似用户。运营需求的例子,比如结合内容运营的需求和用户的自身喜好,为用户主动推送一些运营内容。这个引擎的作用可以理解为推荐系统的精准营销功能,由于已经结合了用户自身的喜好,所以相比于传统的广撒网式tips弹窗运营方法,此方法更可以找到合适的用户来推送合适的内容,从而可以合理地帮助提升运营内容点击转化率和用户满意度。
2.2需要了解已有技术的逻辑框架
产品经理必须在宏观上对技术架构有所了解,才能更好地配合算法工程师完成相应的工作,否者就会出现外行的PM给专业的开发提各种奇怪的需求(例如放着现成的算法不用,班门弄斧地加入一些很粗浅的逻辑);或者避免PM被开发坑,造成很多基础的推荐策略缺失(例如推荐策略中只有CF却没有content based)
以下是一个猜你喜欢的系统框架图范例
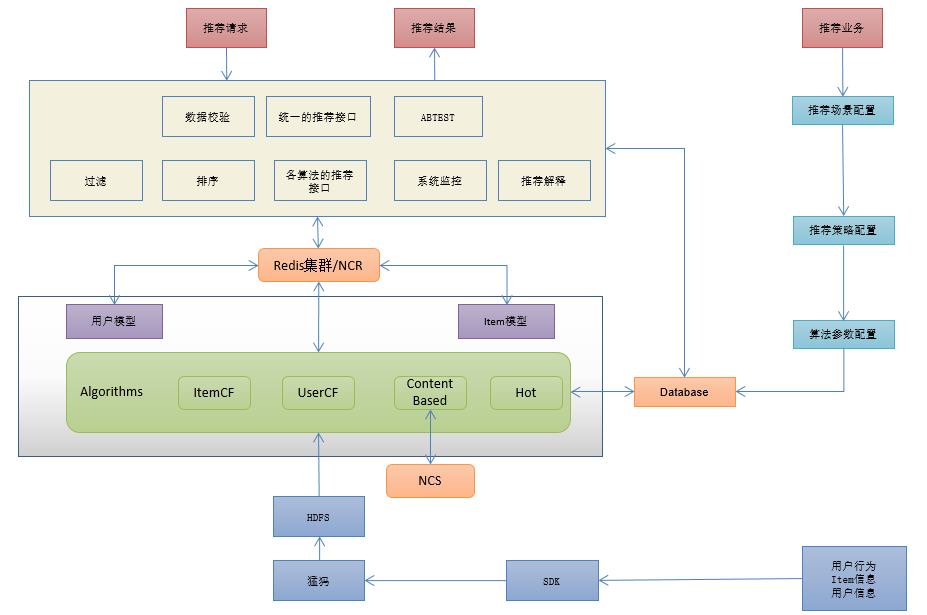
整个架构主要由4部分组成,右上角是推荐场景和参数配置,右下角是行为数据埋点,中部是具体的算法程序,上方是推荐结果的过滤输出校验。
在这个过程中,产品经理主要做的事情如下:
2.2.1推荐场景和参数配置
推荐场景配置就是指推荐业务具体发生的页面,以及其需要搭配的策略,例如“猜你喜欢的音乐”或者“相似音乐”,不同的策略最终会导致系统为其配置的算法搭配方式不同(例如相似音乐就不需要UserCF基于用户的协同过滤策略)
算法参数配置主要指产品内各种行为操作,例如喜欢、评论、分享、点击等行为在该业务中代表的用户对item(物品)的喜好程度,我们需要将其量化为例如-2到+5的区间,比如-2代表讨厌、3代表喜欢、5代表很喜欢,后续算法在计算用户或者物品的相似性时都需要用到这些数据。
2.2.2 埋点数据上报
埋点数据主要包括基于业务自身上报的ItemInfo(物品信息)和ActionInfo(用户行为)
ItemInfo即未来产品业务上需要推荐的物品类型的物品属性数据和用户属性数据。非推荐的物品类型数据可以不用上传。如电商类推荐,只推荐商品,则只需上传用户属性数据和商品属性数据,其他的如评论数据等不需要上传。
Actioninfo主要包括推荐场景下的物品相关行为和非推荐场景下的物品相关行为,前者的作用主要是搜集基础信息用于用户和物品建模以及算法的数据基础,后者主要用来统计算法的推荐效果。
数据上报的准确度直接决定最后的推荐效果,如果一开始上报的数据都不对,即使算法再perfect也无济于事。
2.2.3 推荐算法
这一块就是最复杂的推荐算法和策略了,理论上产品经理们可以不用了解其中的逻辑、概念、公式,就像是产品经理没有必要会编程。但是在从我自身的经历来看,PM能多了解一下算法的基础知识,无论是方便和工程师沟通,还是对接产品需求和实现方式,都大有好处。所以我会简单介绍一下一个推荐系统是如何为用户个性化推荐物品的:

如上图,推荐系统要把海量物品推送给合适的用户,主要依赖以下4种途径:
- 途径1 :首先计算出和你兴趣口味相似的用户,然后与他们有关联的物品(Item)推荐给你,如下图所示

用户关联推荐示意图
确定用户和用户的关系,包括通过社交关系(Social recommendation,真实社交网络上的好友、关注、粉丝等社交关系,即假定你的朋友感兴趣的东西就是你感兴趣的东西),以及通过算法比如CF(collaborative filtering协同过滤)等获得的兴趣或者其它维度上的相似用户(和你兴趣口味相似的用户)。这个过程中,需要重点确立相似性矩阵(用户与用户关系强弱的衡量,比如亲密度、相似度等),用户与用户的关系越紧密,往往兴趣偏好就越接近。
确定用户和物品之间的关系,往往需要我们通过长时间、立体化来观察用户对物品的行为。用户的行为主要分成两种:
? 显式(explicit)的行为:比如:浏览、点击、收藏、分享、购买、评论、点赞、喜欢、不喜欢等;
? 隐式(implicit)的行为,比如:浏览时长、播放时长、浏览次数等
用户各项行为的权重是不一样的,一般用户某个行为所消耗的代价越大,其权重也就相对较高,比如用户购买一个商品比浏览一个商品的代价要大很多,所以购买行为的权重要大于浏览行为的权重;用户完整读完一篇文章然后分享的行为比浏览行为所要付出的时间代价要大很多,所以分享行为的权重要大于浏览行为的权重;这块的研究内容还包括降低热门物品的权重,用户对热门商品的点击行为往往不是用户真实的兴趣,只是从众心理所致或者因为热门商品展示的位置更容易被用户所接触到,而对长尾商品的点击则往往是用户真实的兴趣点;同时用户行为频次方面也需要我们去研究,比如说用户反复查看某个商品或者反复查看某个订阅源,那么用户对这个商品或者订阅源的兴趣相对来说会大一些。相关的研究内容还包括用户行为按时间衰减的影响,一般来说用户的近期的行为往往代表了用户当前主要的兴趣点。
- 途径2:依赖用户对物品(Item)的关系,通过物品推送合适的物品(Item),如下图所示
物品关联推荐示意图

这一条需要确定物品与物品的关系,主要包含相关性和互补性等几种关系,比如通过关联规则,我们可以发现啤酒和尿不湿、尿不湿和奶粉之间的相关性;另外我们发现有些商品之间是有互补性的,比如上衣和下裤,牙膏和牙刷,这种互补性也可以理解为两个商品的搭配性。
确立物品相关性的方式分为基于行为数据和基于提取的特征值。基于行为数据是指,通过大量数据证明对物品A感兴趣的人群也对物品B感兴趣,则证明物品A与B具有相似性;而基于提取的特征值是指,例如物品A和B都具有是描述美食的文章,所以都可以提取出美食这个标签属性,则证明物品A与B具有相似性。前者属于CF(协同过滤),后者属于Item-based Similarity(基于内容的相似性)
- 途径3:依赖用户对特征(feature 可以为显性也可以为隐性,最常见比如tag、类别、矩阵分解中的隐语义等)的关系,通过特征推送合适的物品(Item),如下图所示

物品和人的各种特征抽取,主要用于物品的建模和人的建模以及排序模块。可以认为是提取了物品和人的“DNA”。这些特征既可以是显性特征也可以通过机器学习算法计算出来的隐性特征。研究物品特征和用户特征的意义在于通过从物品和用户中提取尽可能多的特征,通过特征来关联相关物品。
物品特征抽取,拿音乐软件为例,显性特征指歌曲名、歌手名、专辑等固有特征;隐形特征指曲风、节奏、适合的场景、适合的心情等。随着个性化推荐技术的应用和发展,item的特征建模正朝着精细化的方向发展。以新闻个性化推荐中新闻为例,一篇新闻除了自身的文本内容信息外,还可以通过图像识别、语义识别等方式添加更加精准的特征;通过深度学习(DeepLearning)等机器学习技术在特征工程领域的应用,新闻推荐中的资讯类的新闻已从原有的类别、关键词、热度、来源的简单特征,发展出多级类别、多级topic的精细化特征(如多层级的标签树,将不同主题细分成各种子主题,再细分下设内容,才能达到真正的私人定制--例如可以给兴趣为摄影的人推荐tag为艺术的父话题内容);
用户的特征抽取,即用户模型(User Profile),主要由用户的基本属性、兴趣模型、行为模型三部分组成。
基本属性指年龄、性别、地区、教育程度、职业等固有属性(一般由用户主动填写)。
兴趣模型和行为模型的特征维度主要依赖于物品特征抽取:兴趣特征一般通过用户对物品的行为及物品的特征信息建立。这里举例鼎鼎有名的贝叶斯算法,可以通过行为来倒推用户的特征(比如男性模型的特征之一是在阅读新闻时点击军事新闻的概率是40%,而女性模型是4%。一旦一个读者点击了军事新闻,算法就开始逆推TA的性别,加上TA点击其他新闻的行为数据,综合计算,就能比较准确地判断TA的性别)
兴趣特征需要区分短期兴趣和长期兴趣两种类型。所谓长期兴趣就是用户对这个类别一直保持兴趣,不会随时间进行转移,比如某类用户比较喜欢看喜剧类型的电影;短期兴趣,所谓短期兴趣就是一段时间对某个类别比较感兴趣,比如体育,最近一段某类用户对体育感兴趣,但是随着世界杯的结束,用户可能对这个类别的兴趣就消失了。同时区分短期兴趣和长期兴趣可以避免一个流行乐爱好者在某天突然兴趣来潮听了一下午爵士乐后,系统在未来一直为其推荐爵士乐的错误。
- 途径4:依赖用户的上下文信息(时间、地点、设备、天气等),通过上下文信息推送合适的物品(Item),如下图所示
上下文关联推荐示意图

随着大数据技术的发展,记录各种数据变得越来越方便,越来越多的上下文维度被应用到推荐系统中,比如天气、设备信息、时间、地点、季节等等,这些上下文信息的组合使得推荐系统越来越智能、准确,比如用户到达某个商圈附近,根据时间段及用户的历史习惯,推送用户感兴趣的商户打折信息给用户,用户往往就不会太反感。这种推荐在当下使用的概率还不是很高。
2.2.4 展示时机、展示方式
当得到推荐结果后,如何展示、如何排序也会对最终效果产生巨大的影响。
排序问题的基本思路是根据点击率预估排序,主要方式是通过机器学习算法(比如LR、GBDT、深度学习等)。在这个阶段,产品经理的主要任务是根据业务规则提出特定需求。如Facebook的智能动态流,就是根据内容的新鲜度、热度、亲密度和预估的感兴趣程度对所有未读FEED进行排序,帮助用户找到更感兴趣的内容。不仅如此,用户错过的90+%信息中,只有部分内容是对用户具有极高价值且不容错过的,所以这里无需对未读Feed全排序,只需要将最高价值的信息找出来并推荐给用户,其它的Feed仍按正常时间序排列。这样做一方面可以让Feed流整体上符合Timeline的排序,用户感觉自然流畅;另一方面,与用户对最高价值的信息认知上比较接近,算法效果比较理想。产品推出后,用户认可度很高,互动率远远高于普通Feed。
这些都是纯工程师不容易提出的需求,因此需要产品经理协助配合。
此外,推荐内容的展示还需要考虑用户的心理体验,主要包括:
从众:一个人的行为、态度、决策受到他人的影响, 一个典型的例子,就是有些用户不知道选择物品时,会选择热门物品,看看大家都在买的物品或者听的音乐、视频;另外如果产品交互展示能把物品的热度值(比如新闻的跟帖数)展示出来的话,往往会影响到用户后续的决策,比如购买、点击等;
信任:信任是影响用户进行决策(如购买、点击)的一个重要因素,人与推荐系统之间的信任依赖于产品的交互设计及推荐算法的设计。这里很重要的一点就是要给出推荐理由,增加推荐的透明度,增进用户的信任感。增加方便的交互设计,方便用户表达自己的感受,比如不喜欢、扔到垃圾桶并且系统能够智能学习,类似的不喜欢的物品不再推荐,也能增加用户对推荐系统的信任感,当然最基本的一点:推荐系统的推荐结果跟用户的真实偏好越一致,用户对推荐系统的信任度也会越高。
情感:在娱乐类的内容推荐中,如果能识别用户的情感(可以是用户自己表达),往往能增加推荐系统的惊喜度和智能特性,比如电影推荐、音乐推荐等,如果能识别用户的悲伤、欢乐、愤怒等心情往往能大大提升推荐效果。
2.2.5 效果评估和优化
评估一个推荐系统好坏主要通过以下几点:
1、衡量点击和打开率,这说明用户是否对内容感兴趣(需要控制交互和UI的变量)。
2、通过推荐系统替代用户主动搜索或者主动浏览的次数,可以通过横向与使用其他产品对比较,比如使用推荐系统提供内容的用户搜索次数和点击浏览目录次数明显下降。
3、推荐系统的满意度口碑,刨除因为页面位置效果等因素,衡量推荐系统一个重要的就是满意度的口碑问题,这个可以通过单个用户是否有重复使用的行为,曲线是否是一直上升的来衡量,如果一直有新用户访问,但一直没有老用户重复使用,则说明推荐系统还是有待优化。
最终的推荐效果出来之后,还需要根据数据做不断的优化。包括用户的正负反馈的收集等,并以此为依据不断进行优化。
3 未来发展
最近几年,以云计算和大数据为核心的商业生态模型正在快速的转型,用户作为网络中的成员,在通过行为数据的分析和挖掘后,将变得更加立体。而个性化推荐系统,通过大数据的云计算技术,将对用户做出更精准、更全面的分析和画像建模,更智能地为用户提供更加优质和先进的服务。
产品经理
CIO之家 www.ciozj.com 公众号:imciow