我们从搭建单机版的环境开始说起,如果你喜欢看英文版:这里有官方的《quick start》
单机版的部署很简单,我就讲几点比较重要的,首先kafka是用scala编写的,可以跑在JVM上,所以我们并不需要单独去搭建scala的环境,后面会涉及到编程的时候我们再说如何去配置scala的问题,这里用不到,当然你要知道这个是跑在linux上的。第二,我用的是最新版0.7.2的版本,你下载完kafka你可以打开它的目录浏览一下:

我就不介绍每个包里的内容是干嘛的,我就着重说一点,你在这个文件夹里只能找到3个jar包,并且这3个还不能用于后面的编程,而且你也没法在里面找到pom这样用于构建的xml。也别急,也别满世界找,这些依赖库得等你把它放到linux上才会出现(当然需要命令)。
搭建单机版环境,简单的说有那么几步:
1. 安装java环境,我用的是最新的版本jdk7的
2. 将下载下来的kafka扔到linux上,并解压。我用的red het server的linux。
3. 接下来就是下载kafka的依赖包和构建kafka的环境。注意,这一步需要电脑联网。具体命令就是官网介绍的./sbt update 和 ./sbt package。
4. 执行完上面这步大概会花个10多分钟吧,我在自己家里ubuntu没有成功,报了下载不到jline的错。单位里用虚拟机ubuntu成功了,我深刻怀疑是网的问题。上面这不执行完了有两点要注意,一是sbt帮你下载完了所有依赖库,但是这些jar都是分散在各个目录下的,注意区分。二是,这些jar一部分是kafka的编程包,一部分是scala的环境包,上面说了没必要自己去搭scala的环境道理就在这边,你自己去下一个2.9的scala,但人家kafka只支持2.8、2.7。所以编程的时候就用sbt给你下好的包即可。后面讲到编程的时候,会写怎么搭编程环境,很简单的。
上面的步骤都执行完了,环境算是好了,下面我们要测试下是否能成功运行kafka:
1. 启动zookeeper server :bin/zookeeper-server-start.sh ../config/zookeeper.properties & (用&是为了能退出命令行)
2. 启动kafka server: bin/kafka-server-start.sh ../config/server.properties &
3. Kafka为我们提供了一个console来做连通性测试,下面我们先运行producer:bin/kafka-console-producer.sh --zookeeper localhost:2181 --topic test 这是相当于开启了一个producer的命令行。命令行的参数我们一会儿再解释。
4. 接下来运行consumer,新启一个terminal:bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
5. 执行完consumer的命令后,你可以在producer的terminal中输入信息,马上在consumer的terminal中就会出现你输的信息。有点儿像一个通信客户端。
具体可看《quick start》
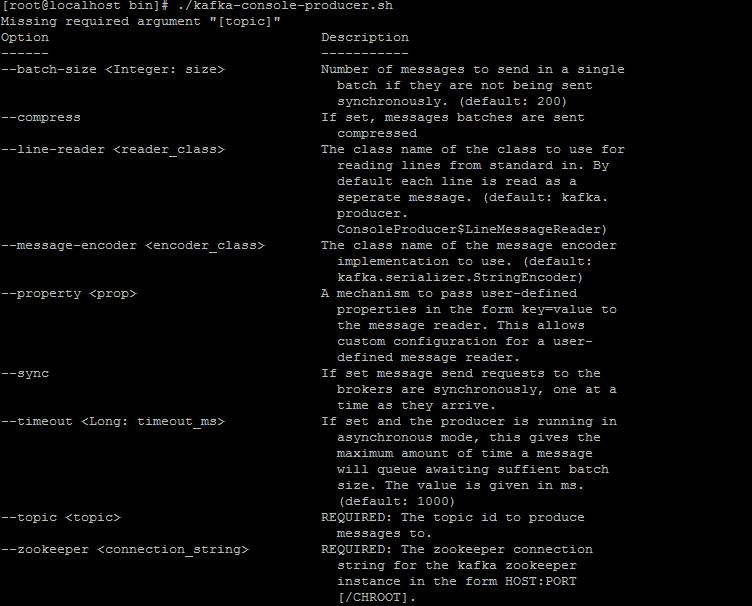
如果你能看到5执行了,说明你单机版部署成功了。下面解释下两条命令中参数的意思。--zookeeper localhost:2181 这个说明了去连本机2181端口的zookeeper server,--topic test,在kafka里,消息按topic来区分,我们这里的topic叫test,所以不管是consumer还是producer都指向了test。其他的参数,我就截图了,首先是producer的参数:
Consumer的参数:

这些参数你可以先看个大概,之后会在编程中使用到,都可以动态的配置。
好了单机版就部署完了,那是不是我把consumer的放到另一台机器上就算分布式了呢。是的,前提是,你还能运行到上面的第5步。在讲配置之前,我们还是将上篇写的分布式来回顾一下,当然我们简化一下情况,按照实际部署的分析:

假设我只有两台机器,server1和server2。我现在想把zookeeper server和kafka server 和producer都放在一台机器上server1,把consumer放在server2上。这当然也叫分布式了,虽然机子不多,但是这个部署成功了,扩展是相当的容易。
我们还是按照那5个步骤来做,当然你肯定能知道,3、4两步的参数要改了,我们假设server1的IP是192.168.10.11 server2的IP是192.168.10.10:
1. 启动zookeeper server :bin/zookeeper-server-start.sh ../config/zookeeper.properties & (用&是为了能退出命令行)
2. 启动kafka server: bin/kafka-server-start.sh ../config/server.properties &
3. Kafka为我们提供了一个console来做连通性测试,下面我们先运行producer:bin/kafka-console-producer.sh --zookeeper 192.168.10.11:2181 --topic test 这是相当于开启了一个producer的命令行。
4. 接下来运行consumer,新启一个terminal:bin/kafka-console-consumer.sh --zookeeper 192.168.10.11:2181 --topic test --from-beginning
5. 执行完consumer的命令后,你可以在producer的terminal中输入信息,马上在consumer的terminal中就会出现你输的信息。
这个时候你能执行出第5步的效果么,是不是报了下面的错了:

我来说原因,在这之前想请你再回去看看《kafka初步》,看看里面讲分布式的内容:
这里的kafka server就是broker,broker是存数据的,producer把数据给broker,consumer从broker取数据。那zookeeper是干嘛的,说的肤浅点儿,zookeeper就是他们之间的选择分发器,所有的连接都要先注册到zookeeper上。你可以把它想象成NIO,zookeeper就是selector,producer、consumer和broker都要注册到selector上,并且留下了相应的key。
所以问题就出在了kafka server的配置server.properties上。Kafka注册到zookeeper上的信息不对,才导致了上面的错误。我们看config中server.properties的配置就可以知道:
# Hostname the broker will advertise to consumers. If not set, kafka will use the value returned
# from InetAddress.getLocalHost(). If there are multiple interfaces getLocalHost
# may not be what you want.
#hostname=
默认的hostname如果你不设置,就是127.0.0.1,所以你把这个hostname设置成192.168.10.11即可,这样你重启下kafka server端,就能执行第5步了。
成功配置的话,你能看到下面的效果,左边的是producer,右边的是consumer,看最下面两行好了,前面的是我之前测试用过的:

如果你还是云里雾里的,建议你回头去看看上篇文章,将kafka分布式基本原理的,kafka实际操作是要建立在对原理熟悉的情况下的。
CIO之家 www.ciozj.com 公众号:imciow