设计目标
传统的离线计算会存在数据反馈不及时,很难保证很多急需实时数据做决策的场景。同时,如果各个业务方自己既负责开发实现各种实时计算程序,同时还需要维护一套实时计算软件环境,不仅效率低效,对公司的开发资源、硬件资源也是极大的浪费。所以为公司提供统一的实时计算平台,提升业务团队开发效率,满足公司各种精细化运营、监控等的要求,我们近期启动**实时计算平台的建设工作。
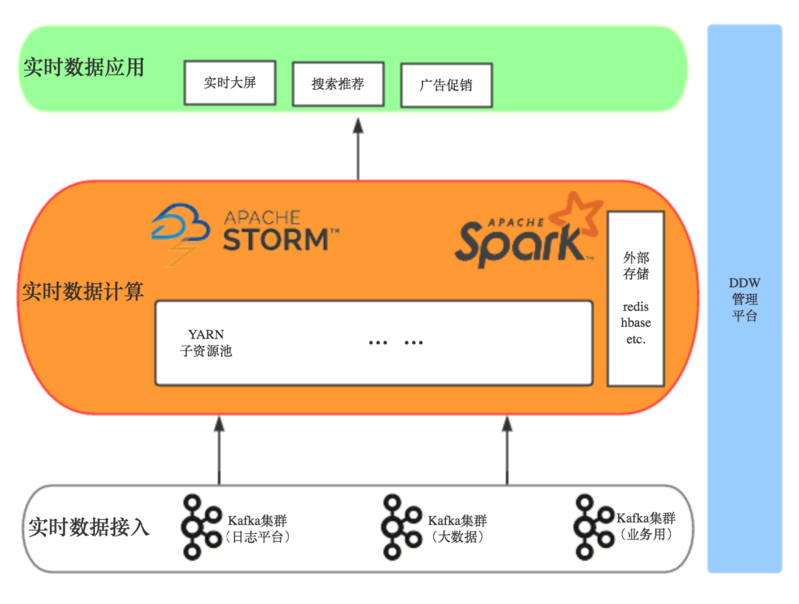
整体架构
设计要点
沿用离线计算平台的权限体系,通过LDAP认证提交任务的用户是否合法。验证过程在任务提交前进行,通过调用ddw-api的接口实现。需要扩展字段表明是否给该账号开通了提交实时任务的权限,防止任何账号都可以提交。(账号合法->未禁用->实时权限->passed)
使用YARN作为资源管理,主要考虑是其本身可与现有权限体系配合,同时很多分布式程序包括Spark,Storm等都提供了on YARN的部署形式。而由于目前的现状是所有离线任务都跑在YARN上面,如果仅仅只是将Spark Streaming任务提交上去,势必会出现离线实时任务混合运行在一起,极易出现资源争抢而影响实时任务。线上集群采用的CDH版本,无法使用社区版基于标签的资源调度方式。
目前采用的方案是对FairScheduler算法进行扩展,具体方式是所有实时任务提交的时候均用特殊标志指定到特殊的queue中,同时传入的参数会告诉RM需要用到哪几台机器给其分配资源。如果不是特殊标志的,统一分配到离线计算专用的一组机器为其分配资源。比如ddw_admin账号在执行离线计算的时候,提交的queue就是root.ddw_admin, 而如果提交实时任务,提交的queue则为root.spark_ddw_admin。在ddw-ui界面中会维护离线计算的节点和实时计算的节点列表,RM会通过api定期获取到离线节点列表。实时计算节点列表是每个实时任务提交的时候通过spark.yarn.applicationTags参数传入的。
这样做以后,就可以将离线计算所用资源和离线计算所用资源从物理上隔离开。对于由统一入口提交的实时任务,都会通过其group_code和token生成一个signature,格式为group_code#hash(group_code,token,key),key为调度服务端写死的一个字符串,这样做的目的是便于以后好清理非法绕过统一提交入口的行为。
目前大数据平台几乎所有定时任务都通过平台自身的任务调度模块完成。为了统一,对于实时计算任务也会采用任务调度模块进行配置、部署和发布。但实时计算任务与之前其他任务的相关配置等都会有所差异,需要单独设计表存储任务元信息和执行历史等。业务方将内容打包成一个uber jar(即包含相关依赖),然后上传到hdfs,配置任务的时候关联到对应的执行包。
由于cdh版本的spark为1.6,目前线上主要提供给搜索推荐团队跑离线任务。实时计算到时会消费业务系统依赖的kafka集群(0.8.2.1)和大数据平台kafka集群(0.9.0.0),目前的鉴权均是依赖dmg的鉴权,如果采用cdh版本spark,无法达到消费不同kafka集群的目的。通过调研,决定采用社区版本spark 2.1作为实时计算的主版本(正好兼容dmg sdk客户端),通过一定技术手段达到了在同一套hadoop集群上同时支持多套不同需求的spark,也为后期进行版本升级改造提供可能。
对于Spark Streaming on YARN方式,当任务正常提交后,会存在一个监控UI页面,通过该入口可以清晰知道任务运行情况,相关环境参数等。比如我们的yarn管理页面为 http://192.168.17.216:8088, 某个Spark Streaming任务id为application_1489730282529_0001, 则可通过 http://192.168.17.216:8088/proxy/application_1489730282529_0001/streaming|[jobs]|[stages]|[environments]|[executors]查看到相关信息。同时Spark提供了部分RESTFul接口,我们也可以通过它获取到部分信息。需要考虑如何将这部分监控日志等信息整合进ddw-ui,采用尽可能低的技术复杂度、尽可能简单的后期维护方式和尽可能易用的展现形式。
一期我们仅仅支持Spark Streaming实时任务,基于Spark 2.1。后面会根据业务情况对其他Spark版本提供支持,也会对其他执行引擎比如JStorm|Storm on YARN提供统一的接入方式。为了尽可能降低学习成本和开发复杂度,我们也会持续关注Apache Beam的相关进展,后面可以根据实际情况引入,这样可以采用统一的编程接口,在不同执行引擎间进行方便切换。
Hive的出现极大方便了人们对结构化大数据的处理,不需要任何简单的统计都自己从头开发MapReduce程序来完成。对于实时计算任务也存在同样的问题,有时可能仅仅是简单的需求,还是需要开发对应的实时计算程序,对业务方来说是挺麻烦的。好在目前实时计算引擎均逐步在开发基于自身的SQL Layer,如华为的StreamSQL,腾讯的EasyCount,Spark的Structure Streaming,阿里的JStorm等。后期也会针对部分简单的实时统计需求,通过界面组件固化生成任务,然后上线运行。
CIO之家 www.ciozj.com 公众号:imciow