这里有一张覆盖机器学习和统计模型的数据科学维恩图。
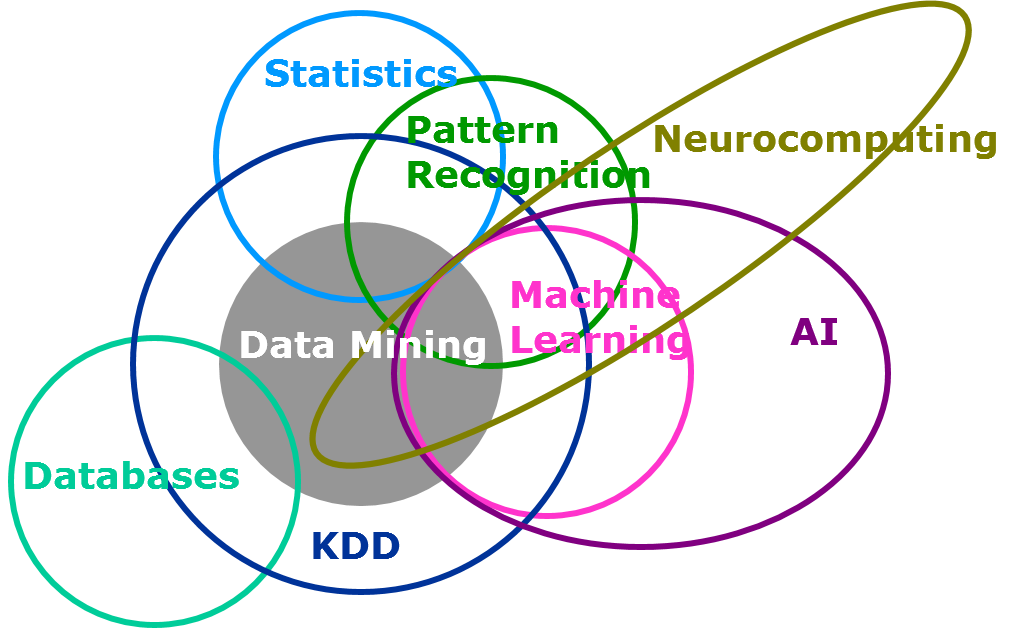
在这篇文章中,我将尽最大的努力来展示机器学习和统计模型的区别,同时也欢迎业界有经验的朋友对本文进行补充。
在我开始之前,让我们先明确使用这些工具背后的目标。无论采用哪种工具去分析问题,最终的目标都是从数据获得知识。两种方法都旨在通过分析数据的产生机制挖掘 背后隐藏的信息。
两种方法的分析目标是相同的。现在让我们详细的探究一下其定义及差异。
定义
机器学习:一种不依赖于规则设计的数据学习算法。
统计模型:以数学方程形式表现变量之间关系的程式化表达
对于喜欢从实际应用中了解概念的人,上述表达也许并不明确。让我们看一个商务的案例。
商业案例
让我们用麦肯锡发布的一个有趣案例来区分两个算法。
案例:分析理解电信公司一段时间内客户的流失水平。
可获得数据:两个驱动-A&B
麦肯锡接下来的展示足够让人兴奋。盯住下图来理解一下统计模型和机器学习算法的差别。
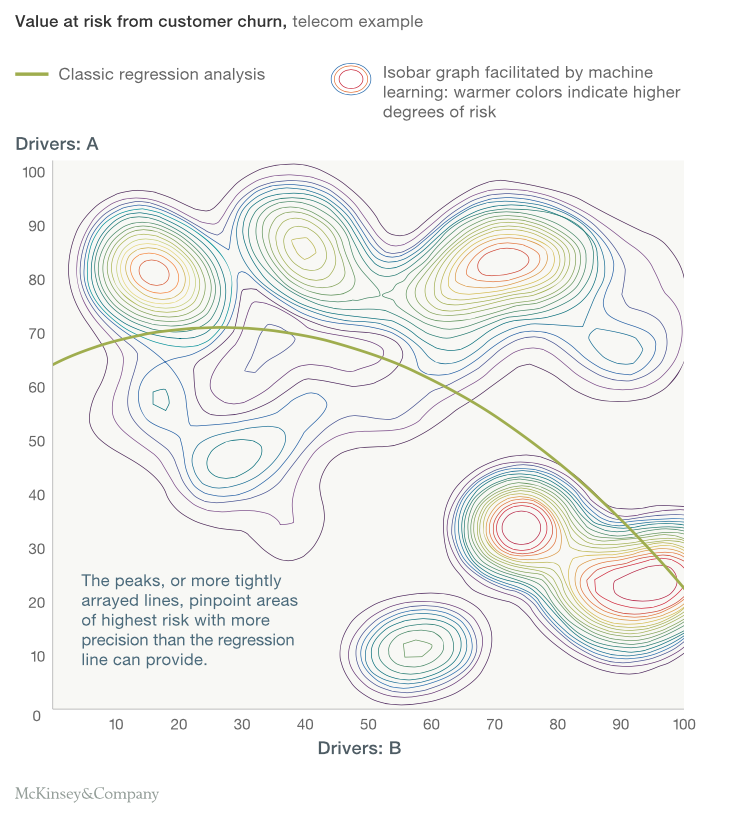
从上图中你观察到了什么?统计模型在分类问题中得到一个简单的分类线。 一条非线性的边界线区分了高风险人群和低风险人群。 但当我们看到通过机器学习产生的颜色时, 我们发现统计模型似乎没有办法和机器学习算法进行比较。 机器学习的方法获得了任何边界都无法详细表征的信息。这就是机器学习可以为你做的。
机器学习还被应用在YouTube 和Google的引擎推荐上, 机器学习通过瞬间分析大量的观测样本给出近乎完美的推荐建议。 即使只采用一个16 G 内存的笔记本,我每天处理数十万行的数千个参数的模型也不会超过30分钟。 然而一个统计模型需要在一台超级计算机跑一百万年来来观察数千个参数。

机器学习和统计模型的差异:
在给出了两种模型在输出上的差异后,让我们更深入的了解两种范式的差异,虽然它们所做的工作类似。
所属的学派
产生时间
基于的假设
处理数据的类型
操作和对象的术语
使用的技术
预测效果和人力投入
以上提到的方面都能从每种程度上区分机器学习和统计模型,但并不能给出机器学习和统计模型的明确界限。
分属不同的学派
机器学习:计算机科学和人工智能的一个分支,通过数据学习构建分析系统,不依赖明确的构建规则。 统计模型:数学的分支用以发现变量之间相关关系从而预测输出。
诞生年代不同
统计模型的历史已经有几个世纪之久。但是机器学习却是最近才发展起来的。二十世纪90年代,稳定的数字化和廉价的计算使得数据科学家停止建立完整的模型而使用计算机进行模型建立。这催生了机器学习的发展。随着数据规模和复杂程度的不断提升,机器学习不断展现出巨大的发展潜力。
假设程度差异
统计模型基于一系列的假设。例如线性回归模型假设:
(1) 自变量和因变量线性相关 (2) 同方差 (3) 波动均值为0 (4) 观测样本相互独立 (5) 波动服从正态分布
Logistics回归同样拥有很多的假设。即使是非线性回归也要遵守一个连续的分割边界的假设。然而机器学习却从这些假设中脱身出来。机器学习最大的好处在于没有连续性分割边界的限制。同样我们也并不需要假设自变量或因变量的分布。
数据区别
机器学习应用广泛。 在线学习工具可飞速处理数据。这些机器学习工具可学习数以亿计的观测样本,预测和学习同步进行。一些算法如随机森林和梯度助推在处理大数据时速度很快。机器学习处理数据的广度和深度很大。但统计模型一般应用在较小的数据量和较窄的数据属性上。
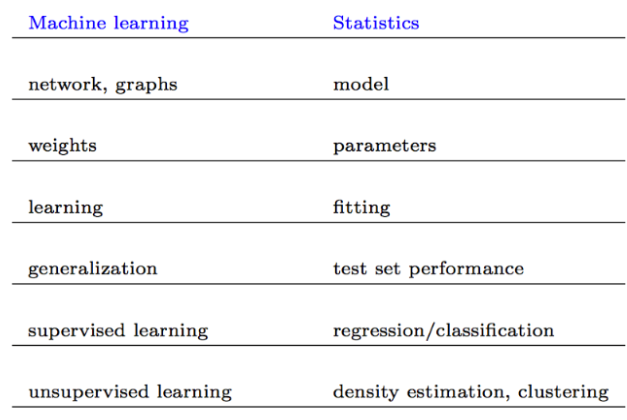
命名公约
下面一些命名几乎指相同的东西:
公式:
虽然统计模型和机器学习的最终目标是相似的,但其公式化的结构却非常不同
在统计模型中,我们试图估计f 函数 通过
因变量(Y)=f(自变量)+ 扰动 函数
机器学习放弃采用函数f的形式,简化为:
输出(Y)——> 输入(X)
它试图找到n维变量X的袋子,在袋子间Y的取值明显不同。
预测效果和人力投入
自然在事情发生前并不给出任何假设。 一个预测模型中越少的假设,越高的预测效率。机器学习命名的内在含义为减少人力投入。机器学习通过反复迭代学习发现隐藏在数据中的科学。由于机器学习作用在真实的数据上并不依赖于假设,预测效果是非常好的。统计模型是数学的加强,依赖于参数估计。它要求模型的建立者,提前知道或了解变量之间的关系。
结束语
虽然机器学习和统计模型看起来为预测模型的不同分支,但它们近乎相同。通过数十年的发展两种模型的差异性越来越小。模型之间相互渗透相互学习使得未来两种模型的界限更加模糊。
CIO之家 www.ciozj.com 公众号:imciow