本文作为下篇,则是从技术角度入手,介绍RTDP的技术选型和相关组件,探讨适用不同应用场景的相关模式。RTDP的敏捷之路就此展开:
本文我们则会推荐整体技术组件选型,对每个技术组件做出简单介绍,尤其对我们抽象并实现的四个技术平台(统一数据采集平台、统一流式处理平台、统一计算服务平台、统一数据可视化平台)着重介绍设计思路;对Pipeline端到端切面话题进行探讨,包括功能整合、数据管理、数据安全等。
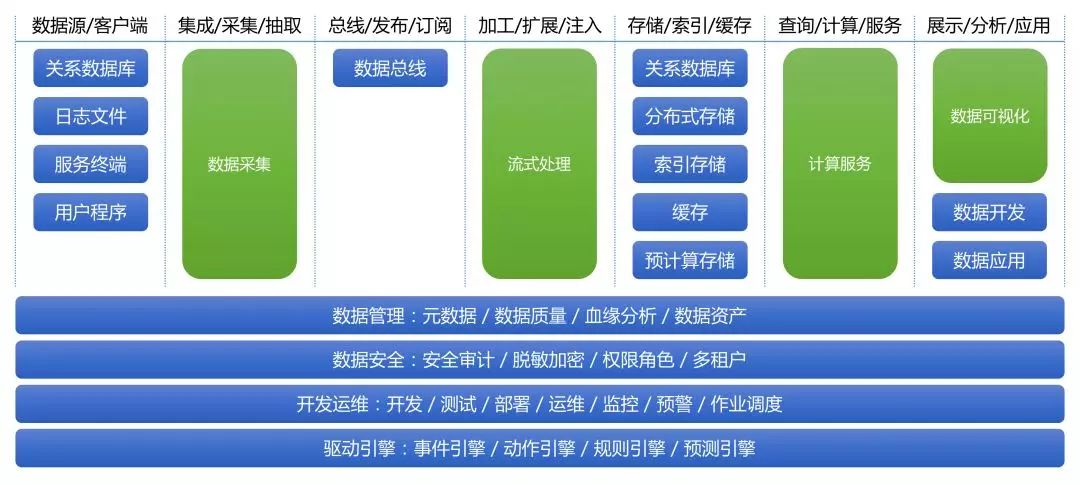
(图1)
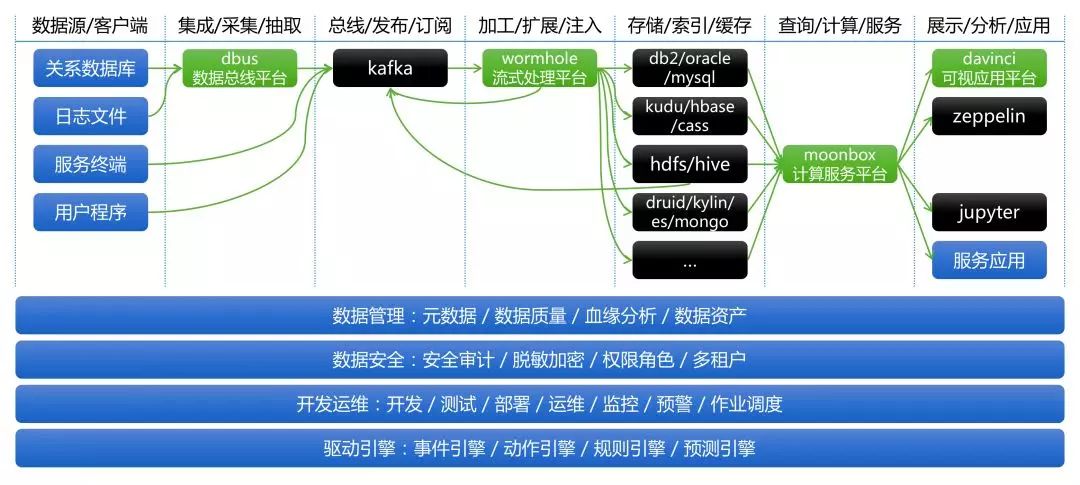
(图2)
首先,我们简要解读一下图2:
数据源、客户端,列举了大多数数据应用项目的常用数据源类型。
数据总线平台DBus,作为统一数据采集平台,负责对接各种数据源。DBus将数据以增量或全量方式抽取出来,并进行一些常规数据处理,最后将处理后的消息发布在Kafka上。
分布式消息系统Kafka,以分布式、高可用、高吞吐、可发布-订阅等能力,连接消息的生产者和消费者。
流式处理平台Wormhole,作为统一流式处理平台,负责流上处理和对接各种数据目标存储。Wormhole从Kafka消费消息,支持流上配置SQL方式实现流上数据处理逻辑,并支持配置化方式将数据以最终一致性(幂等)效果落入不同数据目标存储(Sink)中。
在数据计算存储层,RTDP架构选择开放技术组件选型,用户可以根据实际数据特性、计算模式、访问模式、数据量等信息选择合适的存储,解决具体数据项目问题。RTDP还支持同时选择多个不同数据存储,从而更灵活的支持不同项目需求。
计算服务平台Moonbox,作为统一计算服务平台,对异构数据存储端负责整合、计算下推优化、异构数据存储混算等(数据虚拟化技术),对数据展示和交互端负责收口统一元数据查询、统一数据计算和下发、统一数据查询语言(SQL)、统一数据服务接口等。
可视应用平台Davinci,作为统一数据可视化平台,以配置化方式支持各种数据可视化和交互需求,并可以整合其他数据应用以提供数据可视化部分需求解决方案,另外还支持不同数据从业人员在平台上协作完成各项日常数据应用。其他数据终端消费系统如数据开发平台Zeppelin、数据算法平台Jupyter等在本文不做介绍。
切面话题如数据管理、数据安全、开发运维、驱动引擎,可以通过对接DBus、Wormhole、Moonbox、Davinci的服务接口进行整合和二次开发,以支持端到端管控和治理需求。
下面我们会进一步细化图2涉及到的技术组件和切面话题,介绍技术组件的功能特性,着重讲解我们技术组件的设计思想,并对切面话题展开讨论。
(1) 数据总线平台DBus
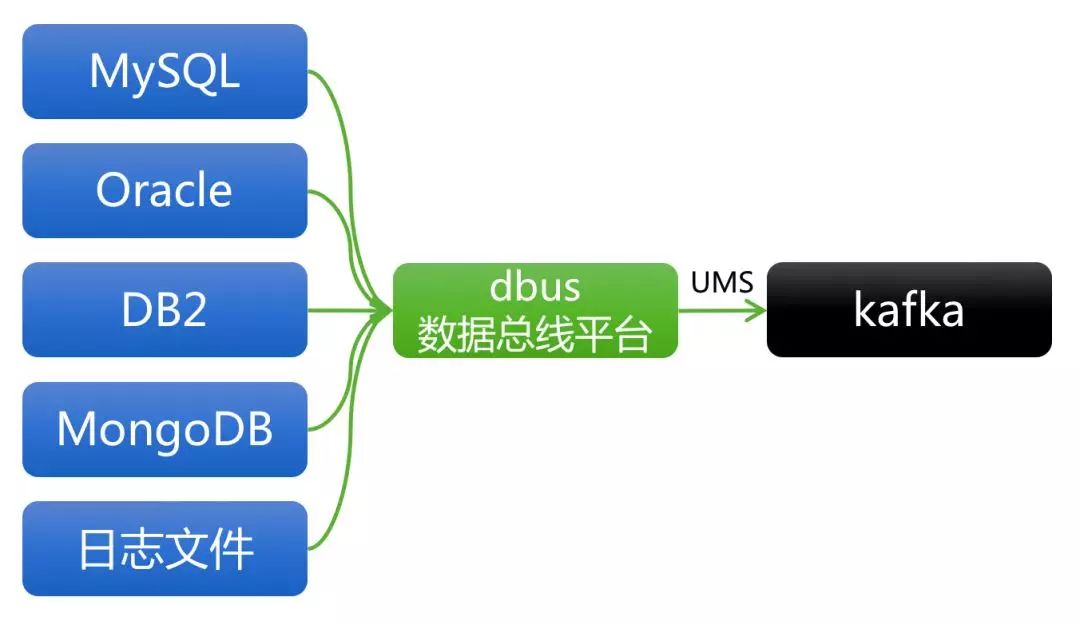
图3 RTDP架构之DBus
DBus设计思想
从外部角度看待设计思想:
负责对接不同的数据源,实时抽取出增量数据,对于数据库会采用操作日志抽取方式,对于日志类型支持与多种Agent对接。
将所有消息以统一的UMS消息格式发布在Kafka上,UMS是一种标准化的自带元数据信息的JSON格式,通过统一UMS实现逻辑消息与物理Kafka Topic解耦,使得同一Topic可以流转多个UMS消息表。
支持数据库的全量数据拉取,并且和增量数据统一融合成UMS消息,对下游消费透明无感知。
从内部角度看待设计思想:
基于Storm计算引擎进行数据格式化,确保消息端到端延迟最低。
对不同数据源数据进行标准化格式化,生成UMS信息,其中包括:
生成每条消息的唯一单调递增id,对应系统字段ums_id_;
确认每条消息的事件时间戳(event timestamp),对应系统字段ums_ts_;
确认每条消息的操作模式(增删改,或insert only),对应系统字段ums_op_;
对数据库表结构变更实时感知并采用版本号进行管理,确保下游消费时明确上游元数据变化。
在投放Kafka时确保消息强有序(非绝对有序)和at least once语义。
通过心跳表机制确保消息端到端探活感知。
DBus功能特性
支持配置化全量数据拉取;
支持配置化增量数据拉取;
支持配置化在线格式化日志;
支持可视化监控预警;
支持配置化多租户安全管控;
支持分表数据汇集成单逻辑表。
DBus技术架构
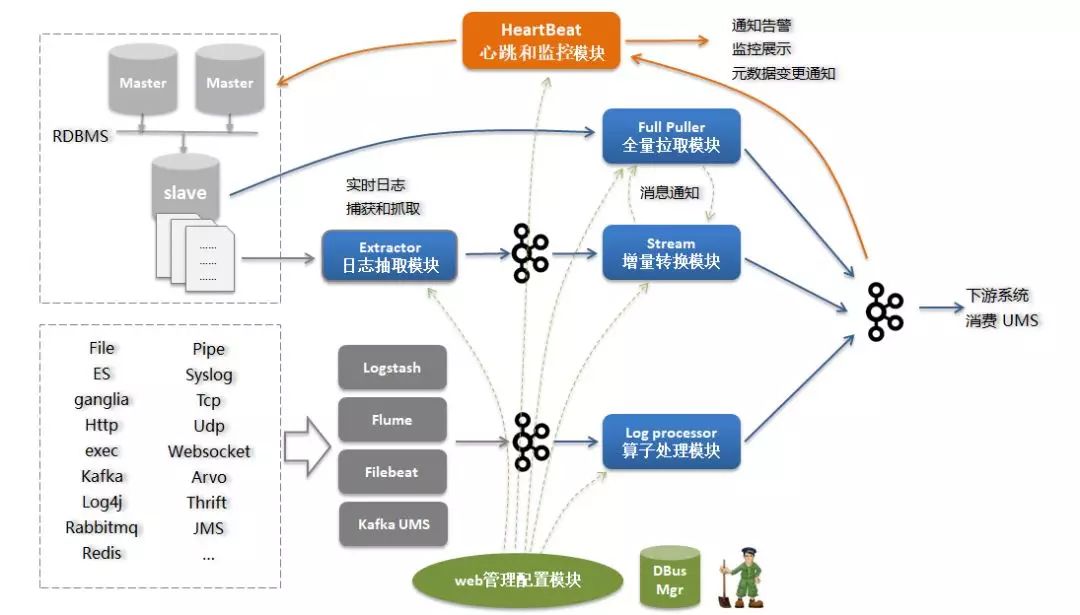
图4 DBus数据流转架构图
更多DBus技术细节和用户界面,可以参看:
(2) 分布式消息系统Kafka
Kafka已经成为事实标准的大数据流式处理分布式消息系统,当然Kafka在不断的扩展和完善,现在也具备了一定的存储能力和流式处理能力。关于Kafka本身的功能和技术已经有很多文章信息可以查阅,本文不再详述Kafka的自身能力。
这里我们具体探讨Kafka上消息元数据管理(Metadata Management)和模式演变(Schema Evolution)的话题。
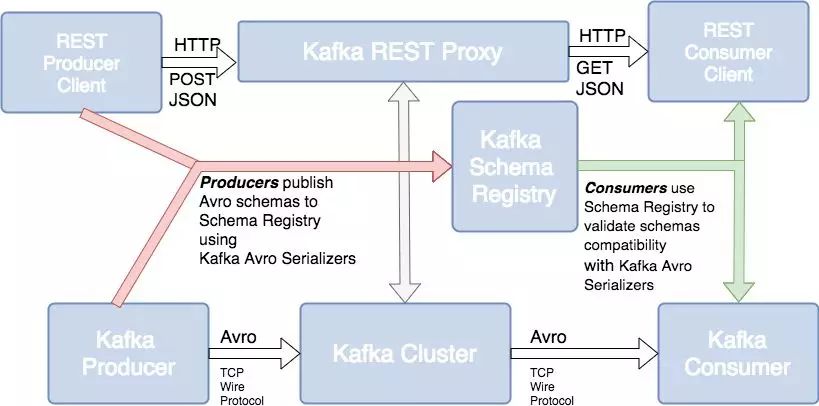
图5 图片来源:
http://cloudurable.com/images/kafka-ecosystem-rest-proxy-schema-registry.png
图5显示,在Kafka背后的Confluent公司解决方案中,引入了一个元数据管理组件:Schema Registry。这个组件主要负责管理在Kafka上流转消息的元数据信息和Topic信息,并提供一系列元数据管理服务。
之所以要引入这样一个组件,是为了Kafka的消费方能够了解不同Topic上流转的是哪些数据、以及了解数据的元数据信息,并进行有效的解析消费。任何数据流转链路,不管是在什么系统上流转,都会存在这段数据链路的元数据管理问题,Kafka也不例外。
Schema Registry是一种中心化的Kafka数据链路元数据管理解决方案,并且基于Schema Registry,Confluent提供了相应的Kafka数据安全机制和模式演变机制。更多关于Schema Registry的介绍,可以参看:
Kafka Tutorial:Kafka, Avro Serialization and the Schema Registry
http://cloudurable.com/blog/kafka-avro-schema-registry/index.html
那么在RTDP架构中,如何解决Kafka消息元数据管理和模式演变问题呢?
元数据管理(Metadata Management):
DBus会自动将实时感知的数据库元数据变化记录下来并提供服务;
DBus会自动将在线格式化的日志元数据信息记录下来并提供服务;
DBus会发布在Kafka上发布统一UMS消息,UMS本身自带消息元数据信息,因此下游消费时无需调用中心化元数据服务,可以直接从UMS消息里拿到数据的元数据信息。
模式演变(Schema Evolution):
UMS消息会自带Schema的Namespace信息,Namespace是一个7层定位字符串,可以唯一定位任何表的任何生命周期,相当于数据表的IP地址,形式如下:
[Datastore].[Datastore Instance].[Database].[Table].[TableVersion].[Database Partition].[Table Partition]
例:oracle.oracle01.db1.table1.v2.dbpar01.tablepar01
其中[Table Version]代表了这张表的某个Schema的版本号,如果数据源是数据库,那么这个版本号是由DBus自动维护的。
由上文可以看出,Schema Registry和DBus+UMS是两种不同的解决元数据管理和模式演变的设计思路,两者各有优势和劣势,可以参考表1的简单比较:
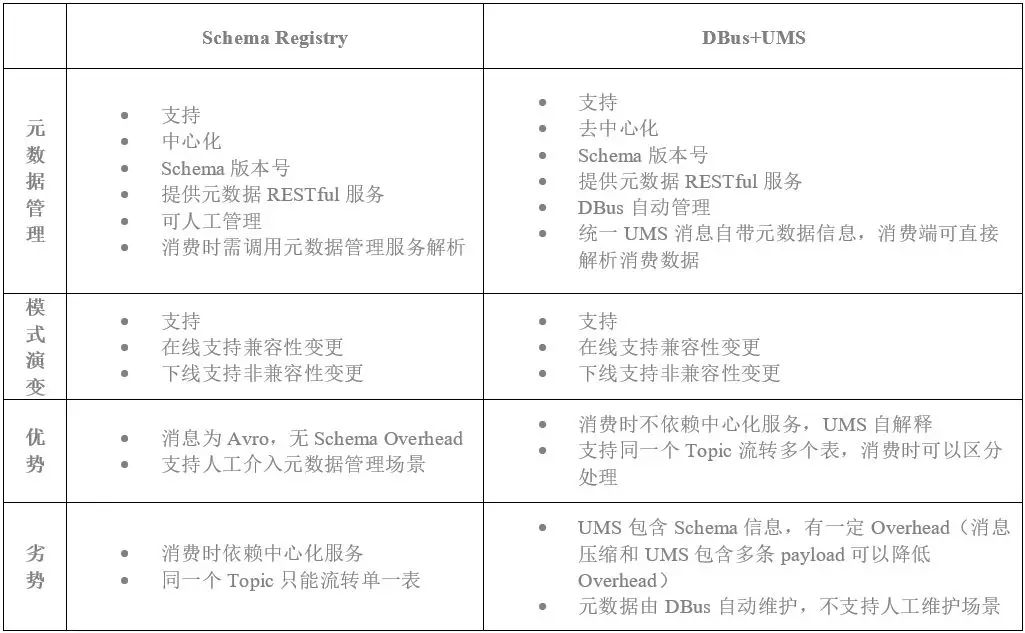
表1 Schema Registry与DBus+UMS对比
这里给出一个UMS的例子:
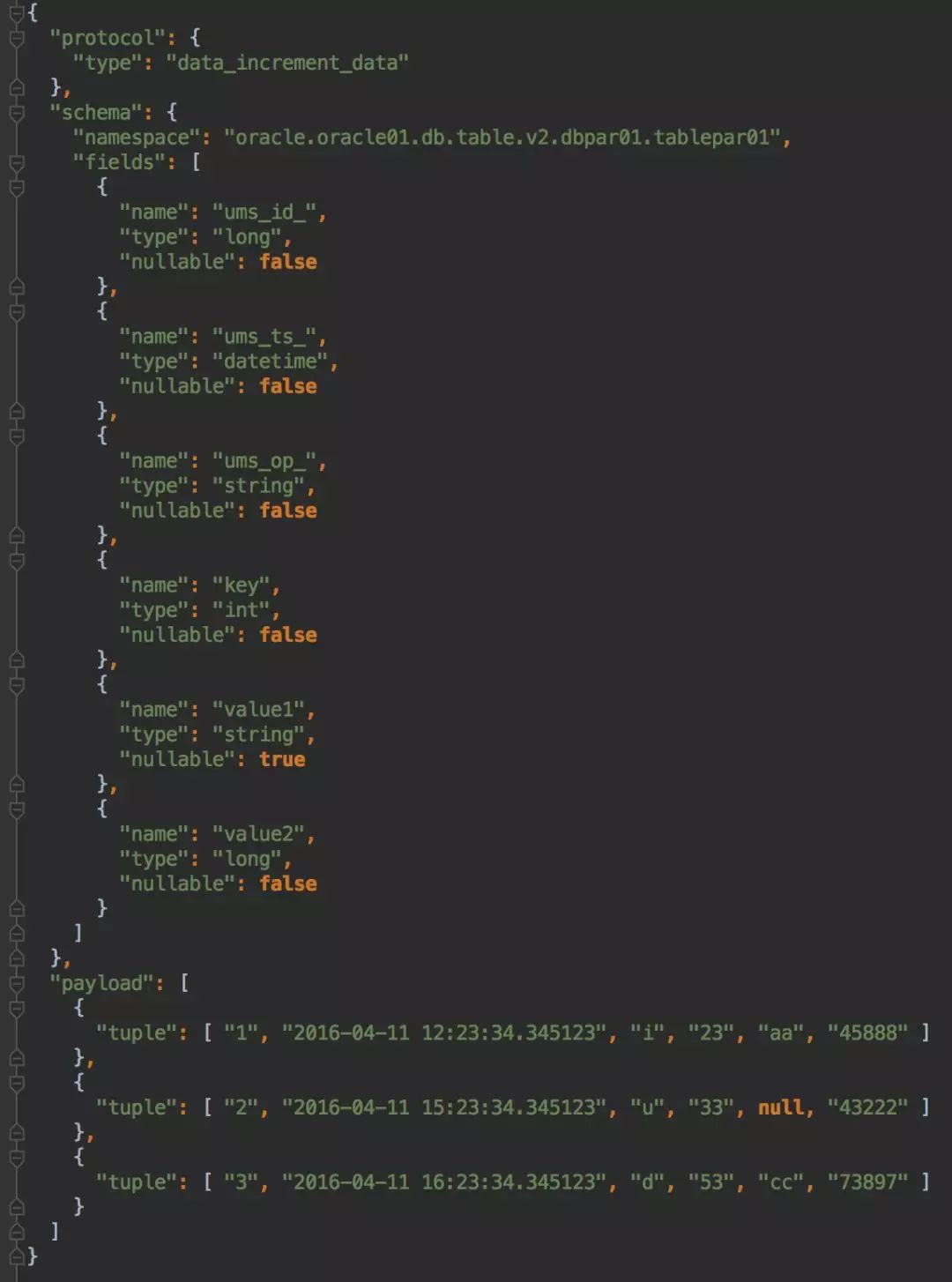
图6 UMS消息举例
(3) 流式处理平台Wormhole
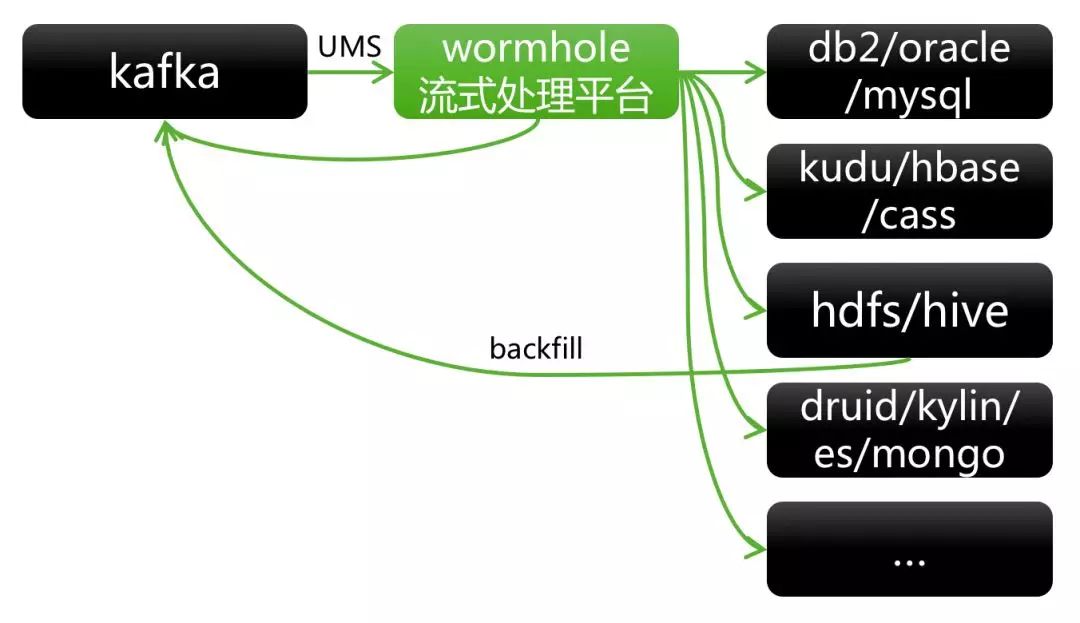
图7 RTDP架构之Wormhole
Wormhole设计思想
从外部角度看待设计思想:
消费来自Kafka的UMS消息和自定义JSON消息。
负责对接不同的数据目标存储 (Sink),并通过幂等逻辑实现Sink的最终一致性。
支持配置SQL方式实现流上处理逻辑。
提供Flow抽象,Flow由一个Source Namespace和一个Sink Namespace定义,且具备唯一性,Flow上可以定义处理逻辑,是一种流上处理的逻辑抽象,通过与物理Spark Streaming、Flink Streaming解耦,使得同一个Stream可以处理多个Flow处理流,且Flow可以在不同Stream上任意切换。
支持基于回灌(backfill)的Kappa架构;支持基于Wormhole Job的Lambda架构。
从内部角度看待设计思想:
基于Spark Streaming、Flink计算引擎进行数据流上处理。Spark Streaming可支持高吞吐、批量Lookup、批量写Sink等场景;Flink可支持低延迟、CEP规则等场景。
通过ums_id_, ums_op_实现不同Sink的幂等入库逻辑。
通过计算下推实现Lookup逻辑优化。
抽象几个统一以支持功能灵活性和设计一致性:
统一DAG高阶分形抽象;
统一通用流消息UMS协议抽象;
统一数据逻辑表命名空间Namespace抽象;
抽象几个接口以支持可扩展性:
SinkProcessor:扩展更多Sink支持;
SwiftsInterface:自定义流上处理逻辑支持;
UDF:更多流上处理UDF支持;
通过Feedback消息实时归集流式作业动态指标和统计。
Wormhole功能特性
支持可视化、配置化、SQL化开发实施流式项目;
支持指令式动态流式处理的管理、运维、诊断和监控;
支持统一结构化UMS消息和自定义半结构化JSON消息;
支持处理增删改三态事件消息流;
支持单个物理流同时并行处理多个逻辑业务流;
支持流上Lookup Anywhere、Pushdown Anywhere;
支持基于业务策略的事件时间戳流式处理;
支持UDF的注册管理和动态加载;
支持多目标数据系统的并发幂等入库;
支持多级基于增量消息的数据质量管理;
支持基于增量消息的流式处理和批量处理;
支持Lambda架构和Kappa架构;
支持与三方系统无缝集成,可作为三方系统的流控引擎;
支持私有云部署,安全权限管控和多租户资源管理。
Wormhole技术架构
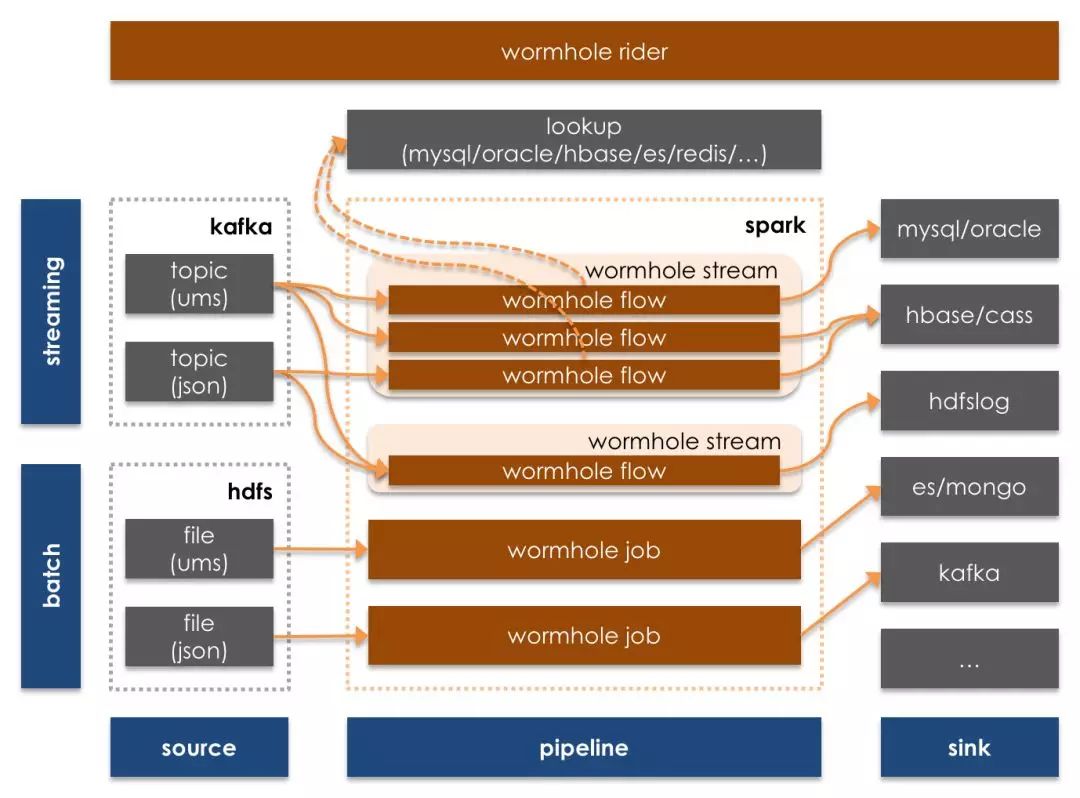
图8 Wormhole数据流转架构图
更多Wormhole技术细节和用户界面,可以参看:
(4) 常用数据计算存储选型
RTDP架构对待数据计算存储选型的选择采取开放整合的态度。不同数据系统有各自的优势和适合的场景,但并没有一个数据系统可以适合各种各样的存储计算场景。因此当有合适的、成熟的、主流的数据系统出现,Wormhole和Moonbox会按照需要相应的扩展整合支持。
这里大致列举一些比较通用的选型:
关系型数据库(Oracle/MySQL等):适合小数据量的复杂关系计算;
分布式列存储系统:
Kudu:Scan优化,适合OLAP分析计算场景;
HBase:随机读写,适合提供数据服务场景;
Cassandra:高性能写,适合海量数据高频写入场景;
ClickHouse:高性能计算,适合只有insert写入场景(后期将支持更新删除操作);
分布式文件系统:
HDFS/Parquet/Hive:append only,适合海量数据批量计算场景;
分布式文档系统:
MongoDB:平衡能力,适合大数据量中等复杂计算;
分布式索引系统:
ElasticSearch:索引能力,适合做模糊查询和OLAP分析场景;
分布式预计算系统:
Druid/Kylin:预计算能力,适合高性能OLAP分析场景。
(5) 计算服务平台Moonbox
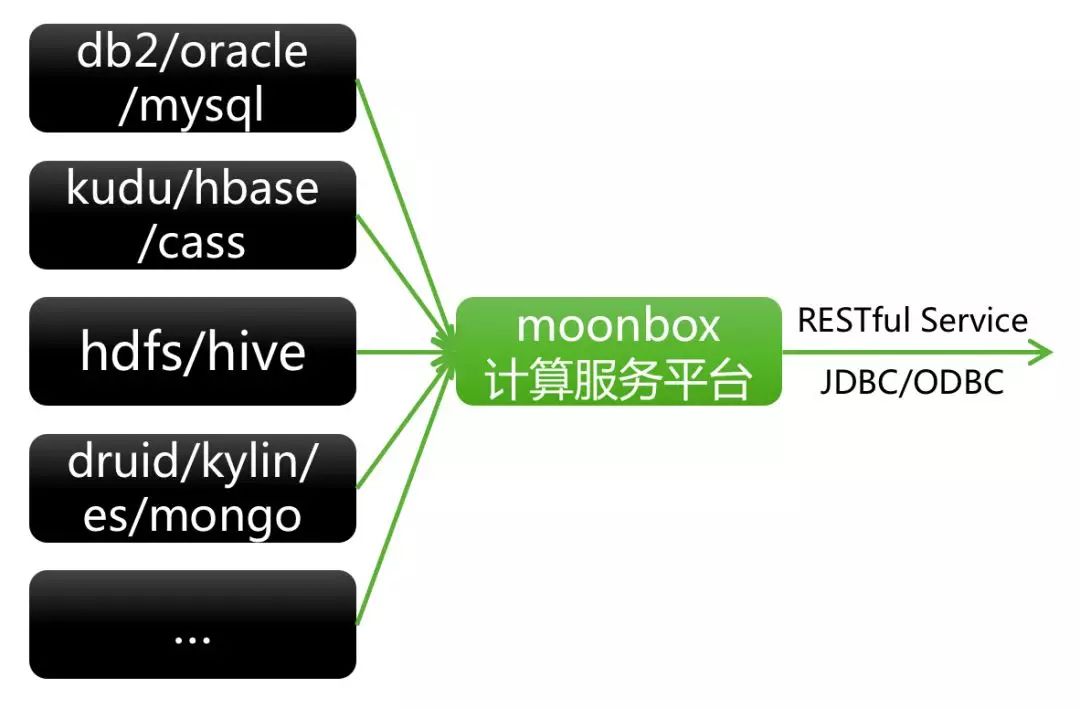
图9 RTDP架构之Moonbox
Moonbox设计思想
从外部角度看待设计思想:
负责对接不同的数据系统,支持统一方式跨异构数据系统即席混算。
提供三种Client调用方式:RESTful服务、JDBC连接、ODBC连接。
统一元数据收口、统一查询语言SQL收口、统一权限控制收口。
提供两种查询结果写出模式:Merge、Replace。
提供两种交互模式:Batch模式、Adhoc模式。
数据虚拟化实现、多租户实现,可看作是虚拟数据库。
从内部角度看待设计思想:
对SQL进行解析,经过常规Catalyst处理解析流程,最终生成可下推数据系统的逻辑执行子树进行下推计算,然后将结果拉回进行混算并返回。
支持两层Namespace:database.table,以提供虚拟数据库体验。
提供分布式服务模块Moonbox Grid提供高可用高并发能力。
对可全部下推逻辑(无混算)提供快速执行通道。
Moonbox功能特性
支持跨异构系统无缝混算;
支持统一SQL语法查询计算和写入;
支持三种调用方式:RESTful服务、JDBC连接、ODBC连接;
支持两种交互模式:Batch模式、Adhoc模式;
支持Cli Command工具和Zeppelin;
支持多租户用户权限体系;
支持表级权限、列级权限、读权限、写权限、UDF权限;
支持YARN调度器资源管理;
支持元数据服务;
支持定时任务;
支持安全策略。
Moonbox技术架构
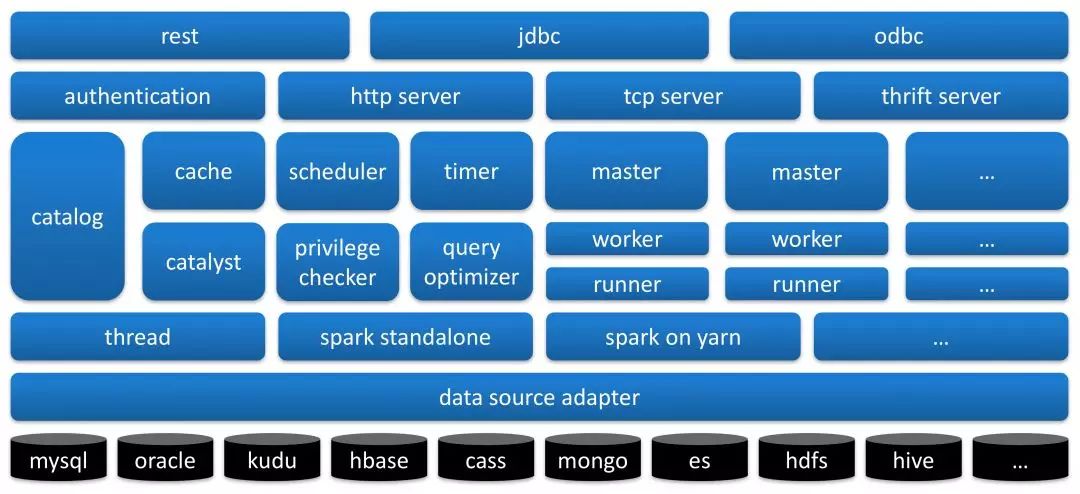
图10 Moonbox逻辑模块
更多Moonbox技术细节和用户界面,可以参看:
(6) 可视应用平台Davinci
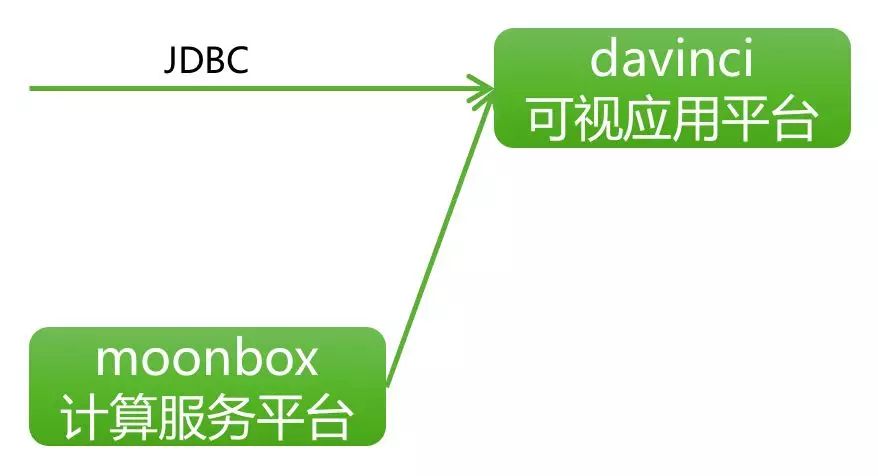
图11 RTDP架构之Davinci
Davinci设计思想
从外部角度看待设计思想:
负责各种数据可视化展示功能。
支持JDBC数据源。
提供平权用户体系,每个用户可以建立属于自己的Org、Team和Project。
支持SQL编写数据处理逻辑,支持拖拽式编辑可视化展示,提供多用户社交化分工协作环境。
提供多种不同的图表交互能力和定制化能力,以应对不同数据可视化需求。
提供嵌入整合进其他数据应用的能力。
从内部角度看待设计思想:
Davinci功能特性
数据源:
数据视图:
支持定义SQL模版;
支持SQL高亮显示;
支持SQL测试;
支持回写操作。
可视组件:
交互能力:
支持可视组件全屏显示;
支持可视组件本地控制器;
支持可视组件间过滤联动;
支持群控控制器可视组件;
支持可视组件本地高级过滤器;
支持大数据量展示分页和滑块。
集成能力:
支持可视组件CSV下载;
支持可视组件公共分享;
支持可视组件授权分享;
支持仪表板公共分享;
支持仪表板授权分享。
安全权限:
更多Moonbox技术细节和用户界面,可以参看:
(1) 数据管理
元数据管理:
DBus可以实时拿到数据源的元数据并提供服务查询;
Moonbox可以实时拿到数据系统的元数据并提供服务查询;
对于RTDP架构来说,实时数据源和即席数据源的元数据信息可以通过调用DBus和Moonbox的RESTful服务归集,可以基于此建设企业级元数据管理系统。
数据质量:
Wormhole可以配置消息实时落入HDFS(hdfslog)。基于hdfslog的Wormhole Job支持Lambda架构;基于hdfslog的Backfill支持Kappa架构。可以通过设置定时任务选择Lambda架构或者Kappa架构对Sink进行定时刷新,以确保数据的最终一致性。Wormhole还支持将流上处理异常或Sink写入异常的消息信息实时Feedback到Wormhole系统中,并提供RESTful服务供三方应用调用处理。
Moonbox可以对异构系统进行即席混算,这个能力赋予Moonbox“瑞士军刀”般的便利性。可以通过Moonbox编写定时SQL脚本逻辑,对关注的异构系统数据进行比对,或对关注的数据表字段进行统计等,可以基于Moonbox的能力二次开发数据质量检测系统。
血缘分析:
Wormhole的流上处理逻辑通常SQL即可满足,这些SQL可以通过RESTful服务进行归集;
Moonbox掌管了数据查询的统一入口,并且所有逻辑均为SQL,这些SQL可以通过Moonbox日志进行归集;
对于RTDP架构来说,实时处理逻辑和即席处理逻辑的SQL可以通过调用Wormhole的RESTful服务和Moonbox的日志归集,可以基于此建设企业级血缘分析系统。
(2) 数据安全
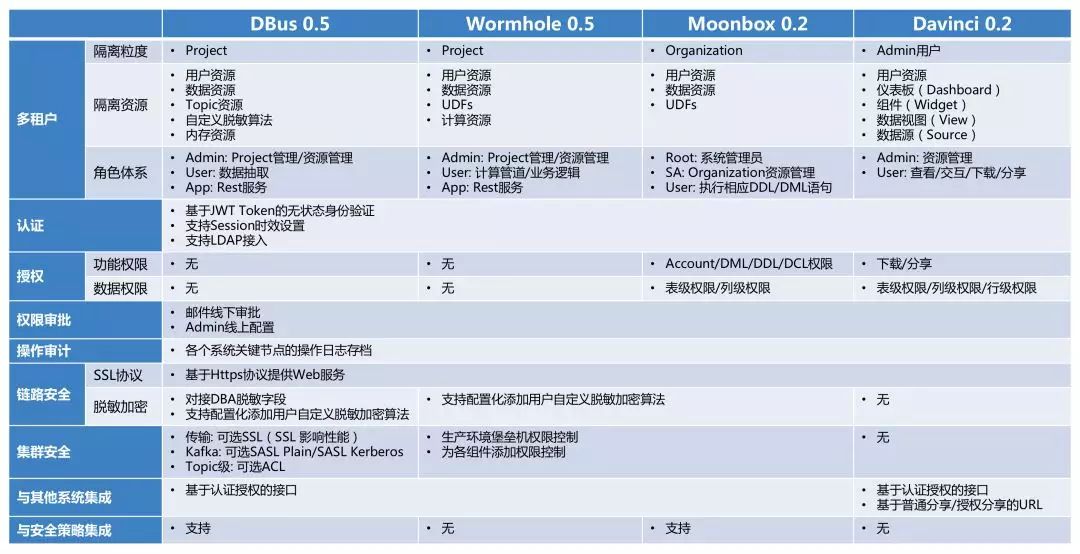
图12 RTDP数据安全
上图给出了RTDP架构中,四个开源平台覆盖了端到端数据流转链路,并且在每个节点上都有对数据安全各个方面的考量和支持,确保了实时数据管道端到端的数据安全性。
另外,由于Moonbox成为了面向应用层数据访问的统一入口,因此基于Moonbox的操作审计日志可以获得很多安全层面的信息,可以围绕操作审计日志建立数据安全预警机制,进而建设企业级数据安全系统。
(3) 开发运维
运维管理:
监控预警:
在介绍了RTDP架构各个技术组件的设计架构和功能特性之后,相信各位读者已经对RTDP架构如何落地有了具体的认识和了解。那么RTDP架构可以解决哪些常见数据应用场景呢?下面我们会探讨几种使用模式以及不同模式适应何种需求场景。
(1) 模式描述
同步模式,是指只配置异构数据系统之间的数据实时同步,在流上不做任何处理逻辑的使用模式。
具体而言,通过配置DBus将数据从数据源实时抽取出来投放在Kafka上,然后通过配置Wormhole将Kafka上数据实时写入到Sink存储中。同步模式主要提供了两个能力:
(2) 技术难点
具体实施比较简单。
IT实施人员无需了解太多流式处理的常见问题,不需要考虑流上处理逻辑实现的设计和实施,只需要了解基本的流控参数配置即可。
(3) 运维管理
运维管理比较简单。
需要人工运维。但由于流上没有处理逻辑,因此容易把控流速,无需考虑流上处理逻辑本身的功耗,可以给出一个相对稳定的同步管道配置。并且也很容易做到定时端到端数据比对来确保数据质量,因为源端和目标端的数据是完全一致的。
(4) 适用场景
跨部门数据实时同步共享;
交易数据库和分析数据库解耦;
支持数仓实时ODS层建设;
用户自助实时简单报表开发;
……
(1) 模式描述
流算模式,是指在同步模式的基础上,在流上配置处理逻辑的使用模式。
在RTDP架构中,流上处理逻辑的配置和支持主要在Wormhole平台上进行。在同步模式的能力之上,流算模式主要提供了两个能力:
(2) 技术难点
具体实施相对较难。
用户需要了解流上处理能做哪些事,适合做哪些事,如何转化全量计算逻辑成为增量计算逻辑等。还要考虑流上处理逻辑本身功耗和依赖的外部数据系统等因素来调节配置更多参数。
(3) 运维管理
运维管理相对较难。
需要人工运维。但比同步模式运维管理更难,主要体现在流控参数配置考虑因素较多、无法支持端到端数据比对、要选择结果快照最终一致性实现策略、要考虑流上Lookup时间对齐策略等方面问题。
(4) 适用场景
(1) 模式描述
轮转模式,是指在流算模式的基础上,在数据实时落库中,同时跑短时定时任务在库上进一步计算后,将结果再次投放在Kafka上跑下一轮流上计算,这样流算转批算、批算转流算的使用模式。
在RTDP架构中,可以利用Kafka→Wormhole→Sink→Moonbox→Kafka的整合方式实现任何轮次任何频次的轮转计算。在流算模式的能力之上,轮转模式提供的主要能力是:理论上支持低延迟的任何复杂流转计算逻辑。
(2) 技术难点
具体实施难。
Moonbox转Wormhole能力的引入,比流算模式进一步增加了考虑的变量因素,如多Sink的选择、Moonbox计算的频率设定、如何拆分Wormhole和Moonbox的计算分工等方面问题。
(3) 运维管理
运维管理难。
需要人工运维。和流算模式比,需要更多数据系统因素的考虑、更多参数的配置调优、更难的数据质量管理和诊断监控。
(4) 适用场景
低延迟的多步骤的复杂数据处理逻辑场景;
公司级实时数据流转处理网络建设。
(1) 模式描述
智能模式,是指利用规则或算法模型来进行优化和增效的使用模式。
可以智能化的点:
Wormhole Flow的智能漂移(智能化自动化运维);
Moonbox预计算的智能优化(智能化自动化调优);
全量计算逻辑智能转换成流式计算逻辑,然后部署在Wormhole + Moonbox(智能化自动化开发部署);
……
(2) 技术难点
具体实施在理论上最简单,但有效的技术实现最难。
用户只需要完成离线逻辑开发,剩下交由智能化工具完成开发、部署、调优、运维。
(3) 运维管理
零运维。
(4) 适用场景
全场景。
至此,我们对“如何设计实时数据平台”这个话题的讨论暂时告一段落。我们从概念背景,讨论到架构设计,接着介绍了技术组件,最后探讨了模式场景。由于这里涉及到的每个话题点都很大,本文只是做了浅层的介绍和探讨。后续我们会不定期针对某个具体话题点展开详细讨论,将我们的实践和心得呈现出来,抛砖引玉、集思广益。如果对RTDP架构中的四个开源平台感兴趣,欢迎在GitHub上找到我们,了解使用,交流建议。
CIO之家 www.ciozj.com 公众号:imciow