今天和大家一起了解知识图谱构建的方法和基本原理。
知识图谱是一个较大的话题。从发展,特点,分类和生命周期等不同的方面都有很多需要讲的东西。
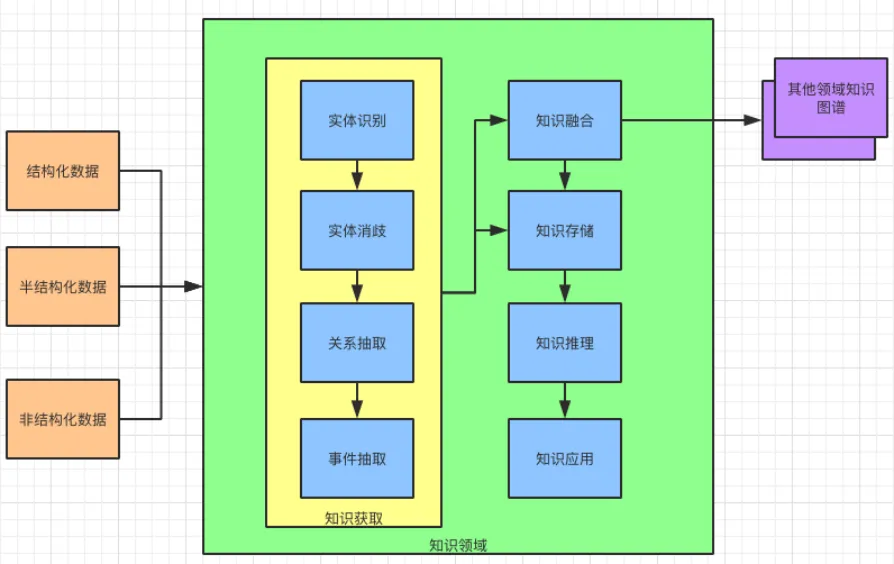
这里我们主要从知识图谱的生命周期作为切入点,讲讲在其形成和使用过程中用到的原理和方法。
①知识体系构建。根据分类,可以把知识图谱分为通用型和领域型。无论是什么类型的知识图谱都需要对其服务的领域进行知识建模。也就是说,采用什么样的方式来表达知识。
②知识融合。一个知识库可以和其他知识库进行融合。在不同领域知识图库进行融合时,会发现来自不同领域,不同语言,甚至不同结构的知识需要做“补充,更新和去重的操作”。
这就是知识融合,一般分为:知识体系融合和实例融合。这部分的操作也可以在构建知识体系的时候统筹考虑。
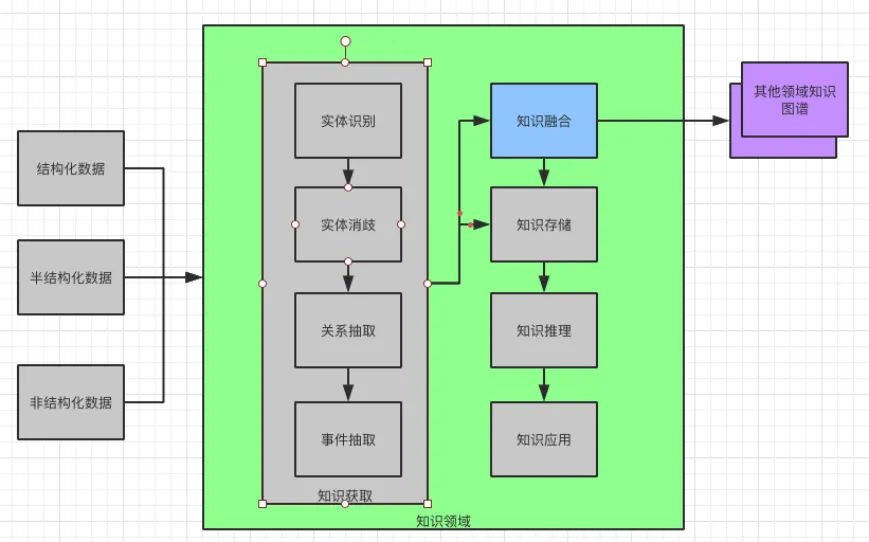
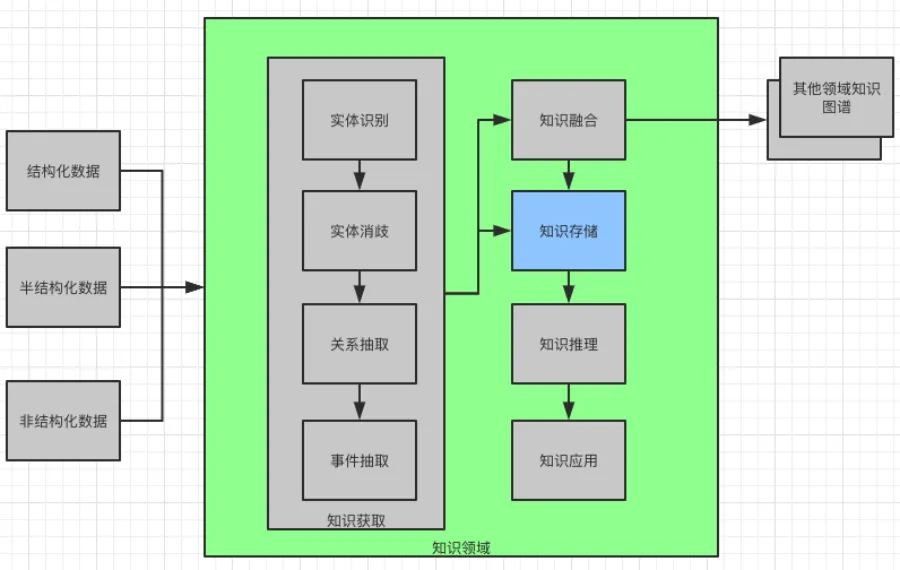
③知识获取。知识获取的目的是从海量的信息(文本)中抽取知识。本文中提到的“获取信息”多为文本信息,因此这里的“获取信息”也是从文本中获取信息的过程。
获取信息结构上划分为三类,分别是结构化信息,半结构化信息和非结构化信息。
从获取信息内容上又分为,实体识别,实体消歧,关系抽取和事件抽取。知识存储在完成了知识抽取和融合之后,就需要将知识存储下来了。
有 RDF(Resource Description Framework,资源描述框架)格式和图数据库两种方式。
因为图数据库对于查询友好,因此被广泛使用,例如:Neo4j。
④知识推理。识别并抽取知识以及存储知识以后,我们会试图挖掘实体(知识)之间隐含的语义关系。
这个过程就是知识推理。例如:已知 A 是 B 的儿子,又知道 B 是 C 的儿子。那么可以推理出 A 是 C 的孙子。
⑤知识应用。识别,抽取,存储和推理的最终目的还是为了应用。知识图谱在搜索,问答,推荐,决策方面被广泛应用。
后面会将上述过程展开讲解,由于知识图谱中包括的内容比较丰富,因此会着重介绍前面几个部分的内容,关于知识推理和知识应用的部分会放到以后的文章中介绍。
我们常说的知识是人类对现实世界的认识,如何将这种认识转化为一种标准的形式呢?因此,需要有一种模型,对其进行描述,从而能够存储到计算机中。
知识图谱的表示方式有多种,有语义网络,框架,脚本。使用比较多的是语义网络模型。
它是通过语义关系连接的概念网络,将知识表示为互相连接的点和边。其中,节点表示为实体,时间,值等信息;边表示实体之间的关系。
例如:马是一种动物,可以表示为如下:
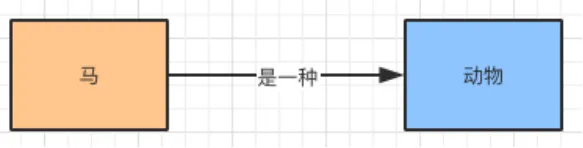
这里的马和动物表示为实体,“是一种”表示它们之间的关系。这也是我们常说的三元组的表现形式。
用 RDF(Resource Description Framework,资源描述框架)可以表述为:
针对关系来说有多种类型的定义:
实例关系:“是一个”。表示一个事物是另一个事物的一个实例。例如:小明是一个人。
分类关系:“是一种”。表示一个事物是另一个事物的种类。例如:篮球是一种球。
成员关系:“个人与集体”。表示一个事物是另一个事物的成员。例如:小王是三年级一班的学生。
属性关系:“一个节点具有另一个节点所表示的属性”。例如:猴子会爬树。
聚合关系:“部分与整体”。例如:手是身体的一部分。
位置关系:事物的方位关系。例如:苹果在桌子上。
相近关系:事物在形状,内容等方面相似。例如:狮子和老虎在森林中都有霸主的地位。
如果将实体通过上述描述,用三元组的方式表示出来,就形成了知识的图状结构,我们把这种结构的表现就叫做知识表现。
上面讲了知识表示,通过三元组表示现实世界的知识。由于知识领域的不同,对事物的概念和定义也会不相同。
例如:“运维”这个词,在软件领域是指对软件的运行维护;在基础设施领域,是指对供配电,空调的运行和维护。
因此,知识图谱是针对具体知识领域而言的。需要根据具体的知识领域,进行“知识体系构建”。
知识体系主要包括三个方面的核心内容:对概念的分类,概念属性的描述以及概念之间相互关系的定义。
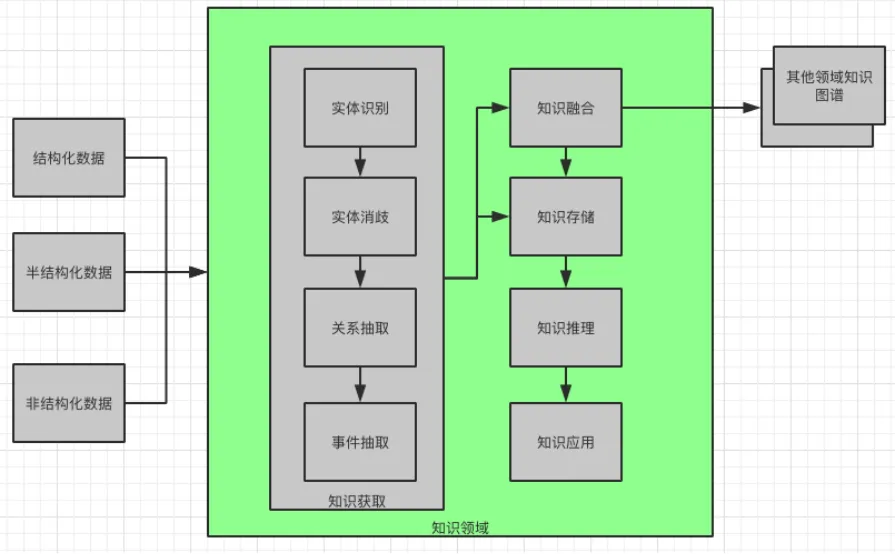
知识领域示意图
知识领域(知识体系结构)就好像知识图谱的框架,它定义了知识的概念,概念的属性以及概念之间的关系。
只有先定义了它,才能再构建知识图谱。如果把知识领域(知识体系结构)理解成 Class 的话,知识图谱就是 Object;如果把知识领域(知识体系结构)理解成骨架的话,知识图谱就是肉体。
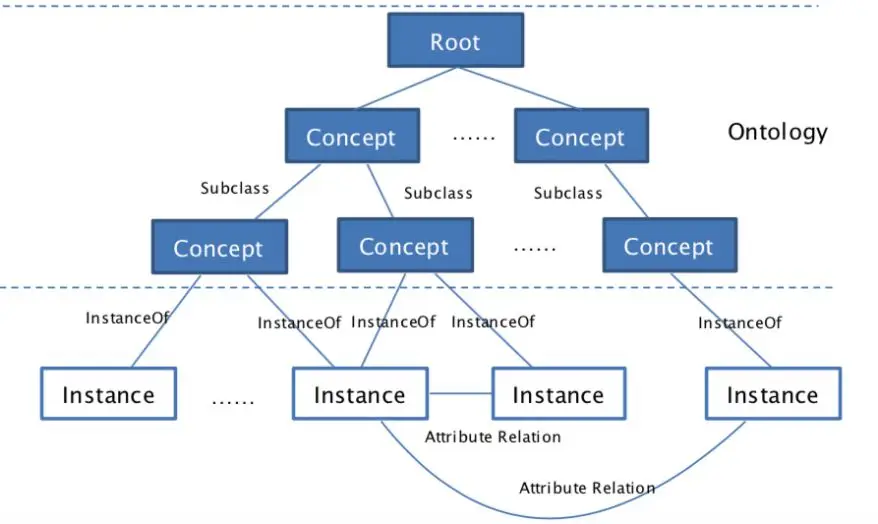
Ontology 对知识进行定义(Concept),根据定义生成实体(Instance)

说完知识领域(知识体系结构)的概念,再来看看通过人工构建需要哪几个步骤。
①确定领域以及任务。这里需要明确几个问题,为什么需要这个领域的知识图谱?其中包括哪些知识?它所服务的人群?以及谁来维护它?
②知识体系整合。由于知识图谱,需要包括海量的知识数据,所以从 0 开始建设成本很高。
因此,需要借助通用知识图谱,领域词典,语言学资源,开源知识图谱的资源。在它们的基础上建立,大大降低成本。
③罗列要素。针对要建立的知识图谱,列出这个领域知识的概念,属性,以及关系等要素。
例如:建立一个人物知识图谱,就要列出科学家,演员,老师,运动员等概念分类。
针对每个分类,定义姓名,年龄,国籍,出生地等属性。以及父母,子女,朋友等关系。
④确定分类体系。就是概念之间的层级关系,类似树状结构。例如体育分类,下面包括体育组织,体育赛事,体育院校等等。可以通过由上至下,或者由下至上的方式建立。

⑤定义属性以及关系。这里的属性和关系的定义具有继承性。例如:演艺人员拥有“年龄”,“毕业院校”,“经纪公司”等属性。演艺人员分类下面包括了歌手和演员。
那么歌手和演员的属性中,除了包括“年龄”,“毕业院校”,“经纪公司”等属性以外,还可能包括其他属性,例如:歌手包括“低/中/高音“;演员包括:”国内/国际影星“。
⑥定义约束。针对上面属性关系的约束关系。例如:年龄为正整数。每个人只有一个母亲(生理学意义上的)。
各个领域知识图谱的构建,导致存在各个垂直领域的知识库。每个知识库为了扩大自身的广度和深度,就需要和其他库做融合。
知识库的融合有两种模式:
竖直方向的知识融合,将通用知识库与专业知识库进行融合。专业知识库中需要一些通用知识库中的通用知识定义,例如:著名人物,地名,公理。
水平方向的知识融合,将相同领域的知识库进行融合。让两个知识库进行数据互补。
知识体系能够在认知和语义层次上对领域知识进行建模和表达,确定领域内共同认可的词汇,通过概念之间的关系来描述概念的语义,提供对领域知识的共同理解。
多个知识体系在融合过程中会产生重叠,会产生许多不同的知识体系。这些不同的知识体系会导致不同的知识图谱难以联合使用。
因此,下面要介绍几种融合的方法:
元素级匹配,将一个词表示为语义向量空间中的一个点,如果词与词之间的相似度高,那么两个点之间的距离就近。表明两个词可以融合。
结构级匹配,通过判断元素属性的定义域和值域匹配度,推断属性的匹配度。
实体对齐,通过判断相同或不同知识库中的两个实体是否表示同一个物理对象的过程。
定义了知识领域和领域之间的融合,就搭建了知识图谱的框架,接下来就要填充内容了。根据三元组理论,知识图谱是由(实体 1,关系,实体 2)组成的。
所以,接下来就要介绍知识获取,它包括实体识别,实体消歧,关系抽取,事件抽取。
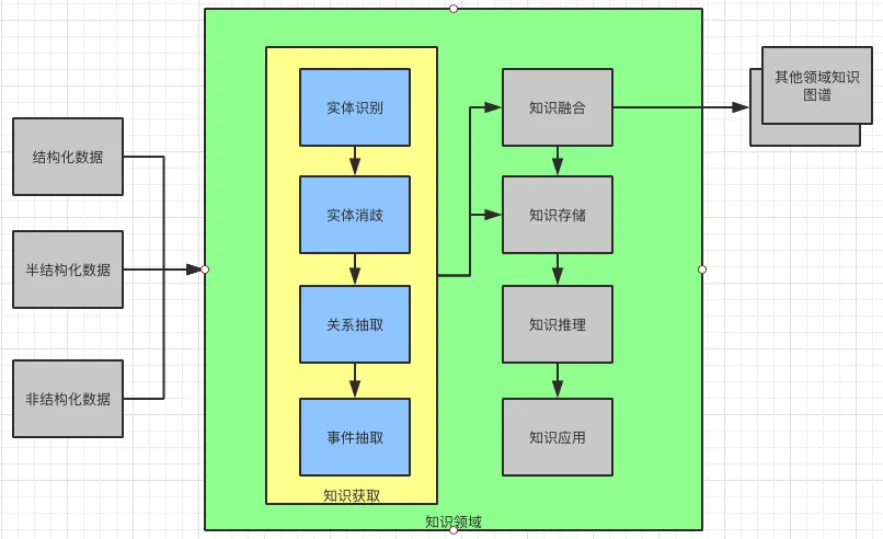
实体(Entity)是知识图谱的基本单元,也是本文中承载信息的重要语言单位。实体识别是抽取文本中命名性指称项。
例如:人名,地名,机构名,产品名。通常意义上分为三大类:实体类,时间类和数字类;七小类:人名,地名,机构名,时间,日期,货币和百分比。
例如:红利小学篮球教练张平出席了会议,他在会议上分享了执教心得。
实体“张平”就有三个指称项,“红利小学篮球教练”是名词性指称项;“张平”是命名性指称项;“他”是代词性指称项。
实体识别抽取有以下几种方法:
①基于规则的方法,通过建立命名实体词典的方法,每次抽取都从文本中查找词典的内容。
②基于特征的方法,通过机器学习的方法利用预先标注好的语料训练模型,使模型学习到某个字或者词作为命名实体组成部分的概率,计算出一个候选字段作为命名实体的概率值。如果大于某个设定的阀值,就抽取命名实体。
③基于神经网络的方法:
特征表示:利用神经网络模型将文字符号特征表示为分布式特征信息。
模型训练:利用标注数据,优化网络参数,训练网络模型。
模型分类:利用训练的模型对新样本进行分类,完成识别。
实体识别完成以后,我们遇到一些问题。两个实体名字一模一样,但在不同的语境下面,表达的内容完全不同。
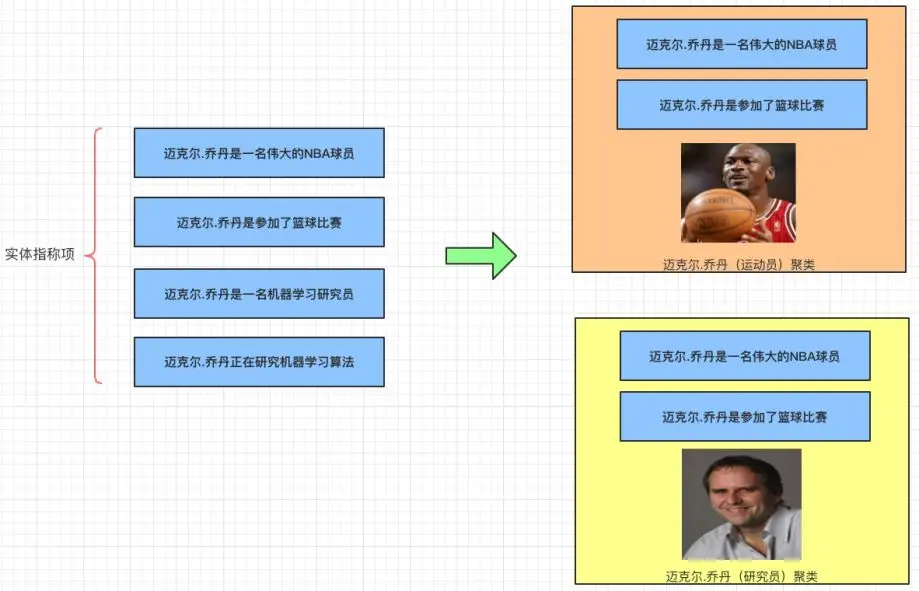
例如:实体指称项,迈克尔·乔丹(Michael Jordan)在不同的文本中,有可能是篮球明星,也有可能是一位机器学习的研究员。
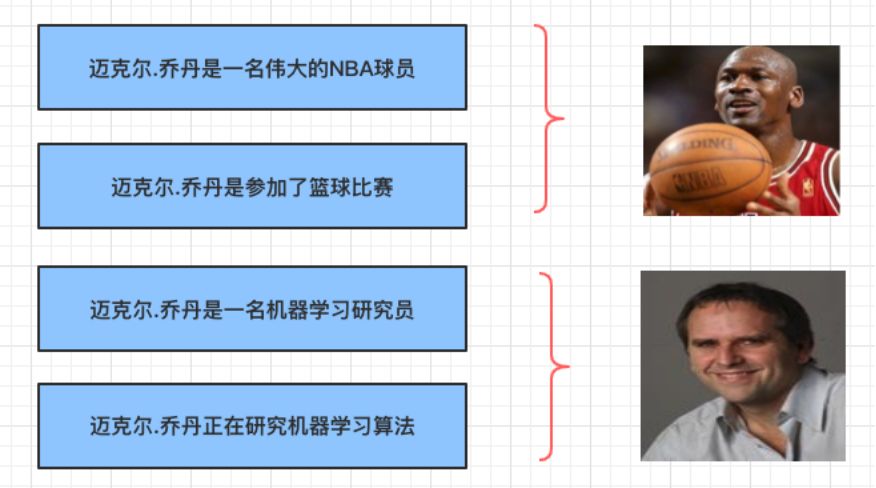
在介绍如何进行实体消歧之前,先介绍几个相关概念,以上图为例:
实体名:迈克尔·乔丹(Michael Jordan)
目标实体列表:迈克尔·乔丹(研究员),迈克尔·乔丹(运动员)
实体指称项:“迈克尔·乔丹” 是 “迈克尔·乔丹(研究员)”的实体指称项。同样,“迈克尔·乔丹”也是 “迈克尔·乔丹(运动员)”的实体指称项。
那么如何消除这种歧义呢?这里有两种歧义消除系统推荐。
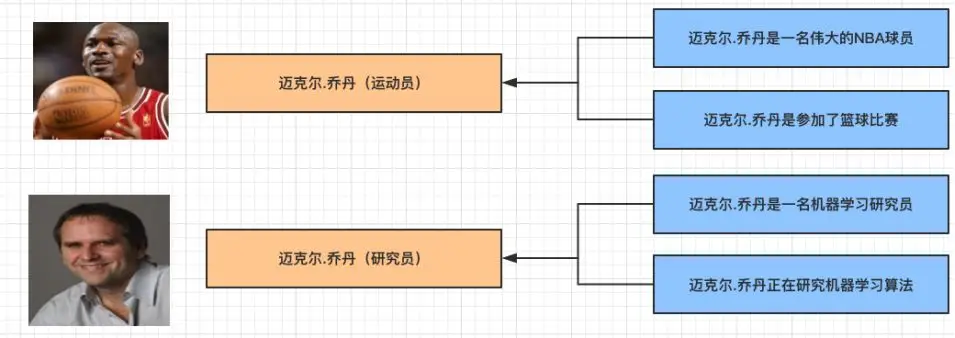
聚类的消歧系统:将同一实体指称项分配到同一类别下面,聚类结果中每个类别对应一个目标实体。
聚类示意图
实体链接的消歧系统:将实体指称项与目标实体列表中对应的实体进行连接实现消歧。
实体链接示意图
上面可以将文本中的实体抽取出来,并且消除它们之间的歧义。接下来,要知道实体之间的关系,就需要用到关系抽取。
关系抽取就是,识别实体之间的语义关系。可以分为二元关系抽取(两个实体)和多元关系抽取(三个及以上实体)。通常表示为(实体 1, 关系, 实体 2)三元组。
根据处理数据源的不同,关系抽取可以分为以下三种:
根据抽取文本的范围不同,关系抽取可以分为以下两种:
根据所抽取领域的划分,关系抽取又可以分为以下两种:
由于篇幅关系,这里对具体关系抽取的方法不展开描述。有兴趣可以自行查找,每个算法都可以单独成为一篇文章。这里我们只需要对关系抽取的分类和方法有基本认识就好。
和关系抽取类似,事件抽取是从文本中抽取出事件并以结构化的形式呈现出来。
首先识别事件及其类型,其次识别出事件所涉及的实体,最后需要确定实体在事件中扮演的角色。
通过一个例子,来介绍几个概念。例如:“小明和小红于 2019 年 12 月 30 日在北京举行婚礼。”
事件指称:具体事件的自然语言描述,通常是一个句子或句群。就是上面这句话的描述。
事件触发词:代表事件发生的词,是决定事件类别的特征,一般是动词或名词。例如:“举行婚礼”。
事件元素:事件中的参与者,主要由实体、时间和属性值组成。例如:“小明”,“小红”, “2019 年 12 月 30 日”。
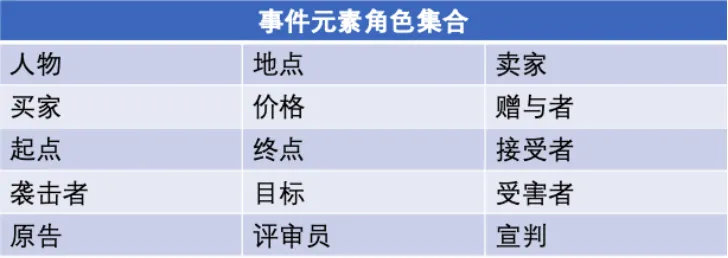
元素角色:事件元素在事件中扮演的角色。例如:“小明”与“小红”扮演的是“夫妻角色”。
事件类别:事件元素和触发词决定了事件的类别,每个分类下面还有子分类。例如:生命,结婚。
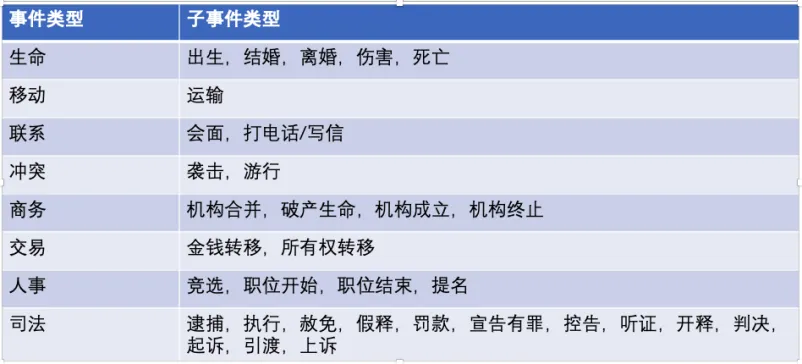
事件类型示意图
事件抽取的方法比较多,基本上分为限定域事件抽取和开放域事件抽取两大类。
在两类中又分为若干小类。这里针对限定域中给予模式匹配的方法给大家做简单介绍。
限定域事件抽取:在进行抽取之前,预先定义好目标事件的类型及每种类型的具体结构(包含哪些具体的事件元素),通常会给出一定数量的标注数据。通过这些标注数据引导事件的抽取。
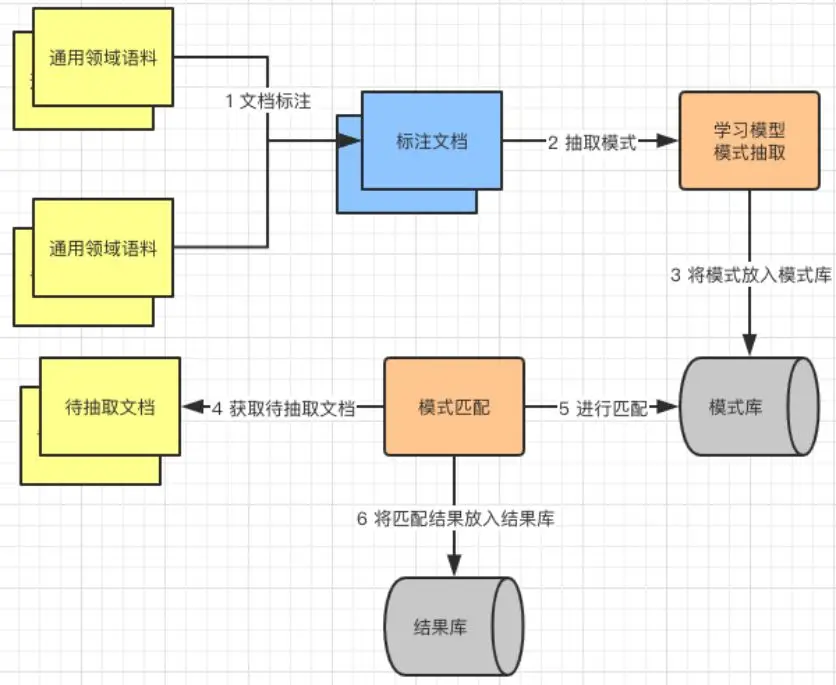
比较有代表的是基于模式匹配的方法,首先通过人工标注语料,再通过学习模型来抽取模式,最后将“待抽取文档”与模式库中的模式进行匹配,生成抽取结果。
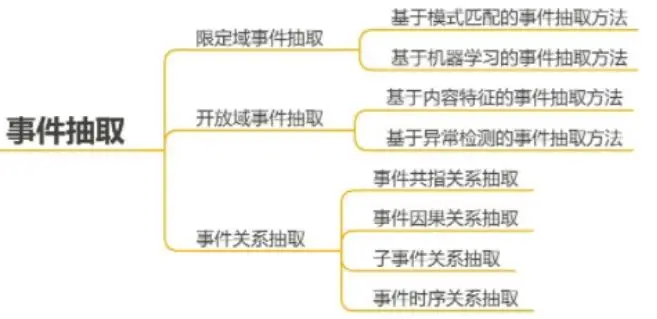
另外,关于事件抽取的方法和关系还有很多,这里不展开描述,放出思维导图供大家参考。
前面提到了知识图谱的架构,知识的抽取,接下来就需要将这些知识(数据)存储下来。并且可以将存储的数据进行检索。
知识存储示意图
谈到存储,需要回到前面说的三元组。知识图谱中的知识是通过 RDF(Resource Description Framework,资源描述框架)构成的。
每个事实被表示为一个形如(subject,predicate,object)的三元组:
subject:主体(也称主语),其取值通常是实体、事件。
predicate:谓词(也称谓语),其取值通常是关系或属性。
object:客体(也称宾语),其取值既可以是实体、 事件、概念,也可以是普通的值(如数字、字符串等) 。
知识图谱的表存放方式有两种,分别是三元组表,类型表。来看看前两种存储的方式。例如:有下图关系。
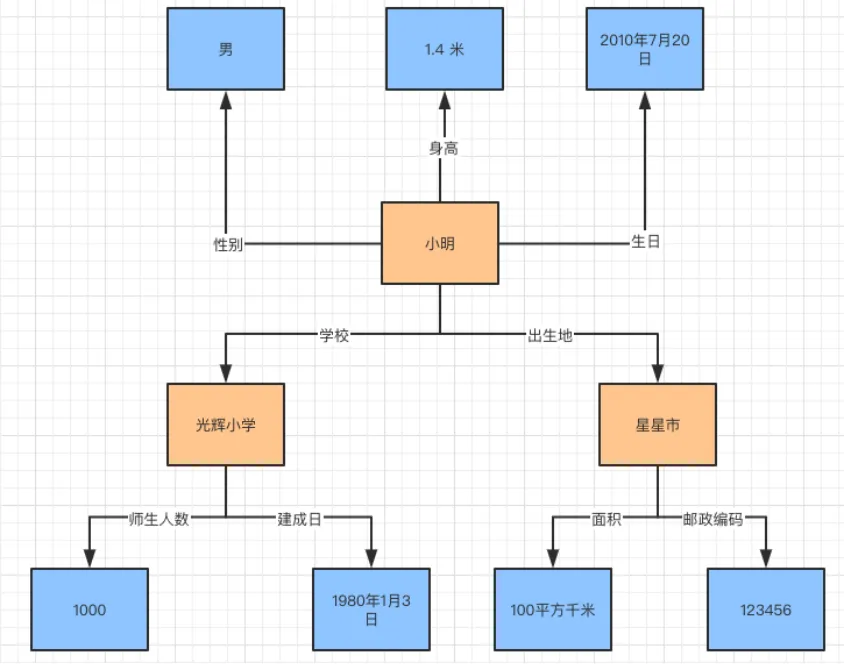
用三元组方式存储:
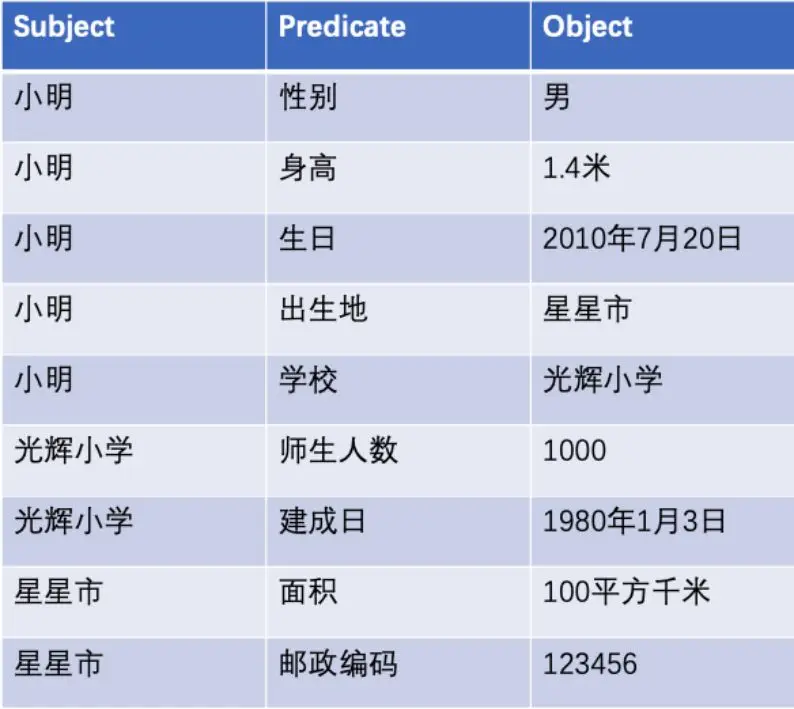
用类型表存储:

图数据库基于有向图,其理论基础是图论。节点、边和属性是图数据库的核心概念。
节点,用于表示实体、事件等对象,可以类比于关系数据库中的记录。例如人物、 地点、电影等都可以作为图中的节点。
边,是指图中连接节点的有向线条,用于表示不同节点之间的关系。例如:夫妻关系、同事关系等。
属性,用于描述节点或者边的特性。例如:姓名、夫妻关系的起止时间等。
来看个例子:

用节点表示实体:刘德华、刘青云、Film:暗战 。
用边表示实体间的关系:刘德华和暗战之间的参演关系、刘德华和刘青云之间的朋友关系等 。
节点可以定义属性:刘德华性别男、身高 174cm、出生地香港等。
边上也可以定义属性:刘德华参演暗战的时间是 1999 年,参演角色是张彼得等。
无向关系需要转化为两条对称的有向关系:刘德华和刘青云之间互为朋友关系。
上面说了按照表方式和图方式的存储,再来看看存储之后如何检索知识信息。知识图谱信息可以通过 SQL 和 SPARQL 搜索来获得。
这里着重介绍 SPARQL,它是 Simple Protocol and RDF Query Language 的缩写,是由 W3C 为 RDF 数据开发的一种查询语言和数据获取协议,被图数据库广泛支持。
和 SQL 类似,SPARQL 也是一种结构化的查询语言,用于对数据的获取与管理。
①数据插入
INSERT DATA { } 包含三元组,不同的三元组通过”.”分割,连续的三元组用”;” 分割。

②数据删除
DELETE DATA {} 包括的三元组,不同的三元组通过”.”分割。

这里的 s,p,o 分别对应的是 subject,predicate 和 object。这样和刘德华这个节点的相关信息都删除了。但是刘青云和暗战对应的节点和关系依旧存在。

③查询语句
和上面两个语句类似,例如要查询身高为 174cm 的男演员。

如果说知识图谱本身就是一个知识的数据库,那么知识领域(知识体系结构)就是这个数据库的框架。
在建立知识图谱之前我们需要对知识体系进行搭建,同时要解决知识融合的问题。
有了知识体系结构,就可以进行知识获取,这里包括实体识别,实体消岐,关系抽取和事件抽取。
实体识别有基于规则,特征和神经网络的识别方法。实体消岐可以通过聚类和实体连接的方法搞定。
关系抽取和事件抽取,根据数据源,文本范围和领域划分的不同,方法各有千秋。知识抽取以后需要做知识的存储,其中有表存储和图存储两种方式。
目前比较流行的是图存储的方式。并且基于图存储的方式,还提供了 SPARQL 查询语言对数据进行管理。
CIO之家 www.ciozj.com 公众号:imciow