从 2013 年 4 月正式上线至今,网易云音乐平台持续提供着:乐屏社区、UGC(User Generated Content)歌单、以及精准推荐等服务,孵化出了音乐人计划、LOOK 直播、以及主播平台等版块。
目前云音乐的注册用户有 6 个亿,而且持续在音乐类 App 排行榜里蝉联着第一的位置。

在音乐推荐的实际应用场景中,我们采用了 AI 技术来分发歌曲与歌单。其中比较典型的应用是:每日歌曲和私人 FM,它们能够根据个性化的场景,进行相关曲目的推荐。
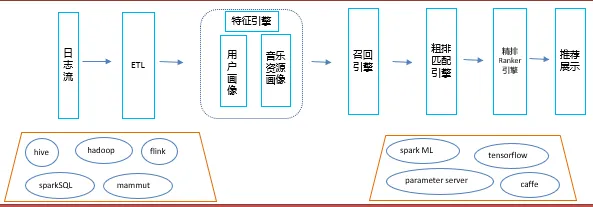
上图是我们整个音乐推荐系统的逻辑图,包括各种日志流、ETL、特征、召回、排序和最后的推荐。
对于该推荐系统而言,最主要的是如何理解用户的画像,也就是通过对前端数据进行整合,了解用户具体喜欢什么样的音乐。
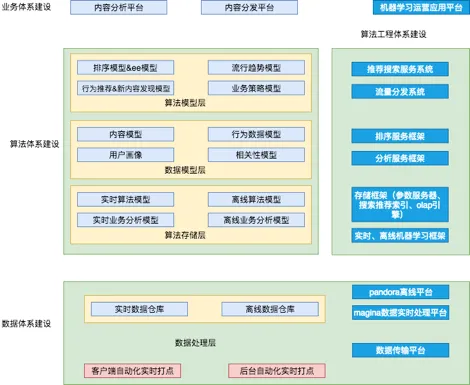
如上图所示:
在数据层,我们主要用到了 Hive、Hadoop、Flink、SparkSQL 和 Mammut。
在机器学习层,我们则用到了 SparkML、Tensorflow、Parameter Server 和 Caffe。
上面是数据体系建设的对比图,其中,算法体系建设包括了针对用户体系的建设,这是云音乐 AI 算法的应用环境。
而我们的团队则主要分为:
数据体验团队
人工智能算法团队
中台团队
业务相关的成员

到采用人工智能的推荐方式,音乐类推荐与其他商品有着不同的地方。例如:
由于我们能够在很短的时间分辨出自己的喜好,所以我们可以做到在 10 秒钟内浏览十来条连衣裙。
但是音乐是需要花时间去体验的,往往一首曲子我们听了 10 秒钟或者更长的时间后,才发现它并非我们所喜好的。
所以说,音乐不是通过直接看就能被理解的,我们在制作推荐产品的过程中,应该以用户的体验为导向,真正去理解音乐的本身。
连衣裙往往在单位时间内只能被消费一次,但是人们可以通过循环播放列表、以及单曲循环的方式,在单位时间内反复欣赏音乐。因此,这是一种可重复消费的行为,我们在做推荐时应当把握此规律。
由于音乐消费的成本比较高,我们更需要重视用户的体验,以及用户在其消费过程中存在的、较强的时间先后关联性。
同时,是否给让用户收听一首歌曲的 10 秒、30 秒、以及 60 秒,对他们来说其表达的含义是截然不同的。
因此,我们需要提供的是真正有意义的消费,从而让这些关联性体现出有效的行为含义。
怎么去衡量音乐推荐系统的优劣呢?是考察用户使用该平台的时长?还是看他在收藏夹内收藏的音乐曲目数?当然,我们曾经发现有些用户从来不以点击红心的方式去收藏任何歌曲。
后期通过交流,我们才发现他其实只是直接把自己碰到的不喜欢的歌曲拉黑了而已。可见,我们很难用单一目标去衡量音乐推荐系统的效果。
下面我们来看看,云音乐平台是如何应用各种 AI 技术的:
①音乐的复杂性
鉴于上面提到的有关音乐的复杂性问题,我们该如何去理解音乐呢?在我们的平台上,针对不同的音乐,有着丰富的 UGC、以及各式各样有质量的用户评论。
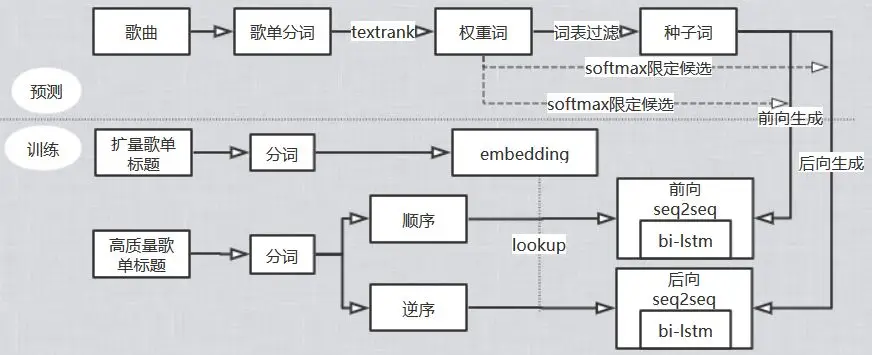
因此,我们可以运用这些针对歌单的评论与认知,采用双向的 bi-Istm,来针对音乐生成一些描述性的语句。
那么,当有新的音乐被输入时,我们便可以基于与之相关的较少的语言,来制定出一个新的解释性描述。

如上图所示,例如有一首《逆流之河》的歌曲,其下方有着许多相关的歌单标题和描述信息。
我们可以通过新增关键词,来还原各种标记词,进而产生对于该音乐人的相关特征描述。
在此基础上,我们再根据人工过滤的词汇表,自动生成诸如:“网络的华语女声”、“香港民谣歌曲”等短语。
因此,凭借着该 NLP(自然语言处理)系统,我们最终能够实现歌曲短语的可视化。
籍此,对于社区里的用户来说,他们甚至可以不用点开某个歌曲收听,就能够大致获悉该歌曲所归属的类型。
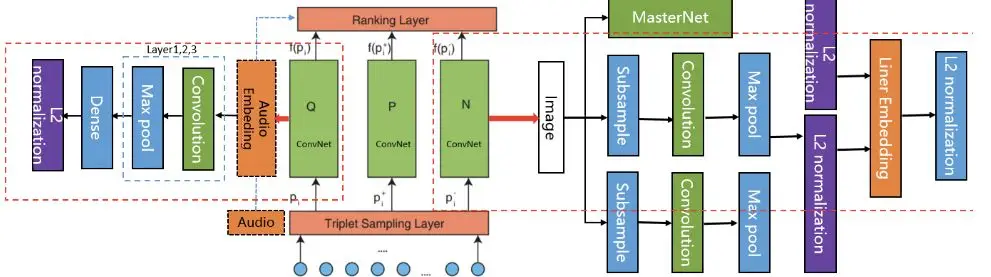
其次,我们可以利用比较简单的“视频+图像+卷积”技术,来理解音乐。
例如,对于一些比较热门的歌曲,我们利用已生成的表达、以及现有的关联性,进而获取相关的音频,识别歌曲的响度、节奏、风格、以及音乐之间的相似性,给音乐进行“画像”。
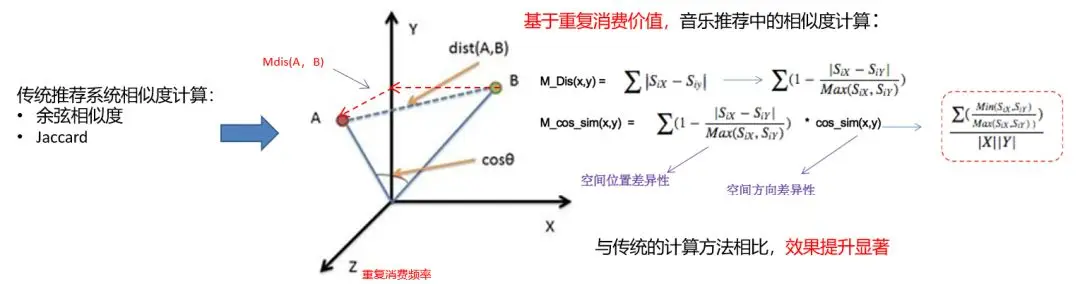
②音乐中的重复消费价值
这里主要体现的是音乐推荐中的 CF。如上图所示,我们通过跟踪发现:某个用户将 A 歌曲听了 10 次,将 B 歌曲听了 9 次,而 C 歌曲只听了 1 次。
那么我们就可以对 A、B、C 的相似关联性理解为:该用户偏好 A 和 B 类歌曲更多一些,而且 A、B 之间的关联性也更大一些。
因此,基于用户的此类重复消费频次,我们可以通过设置 X、Y、Z 坐标轴的关系,来表达它们之间的空间位置、以及空间方向的差异性。
显然,有了此类相似度的计算,我们对于各种音乐的推荐效率会有大幅的提升。
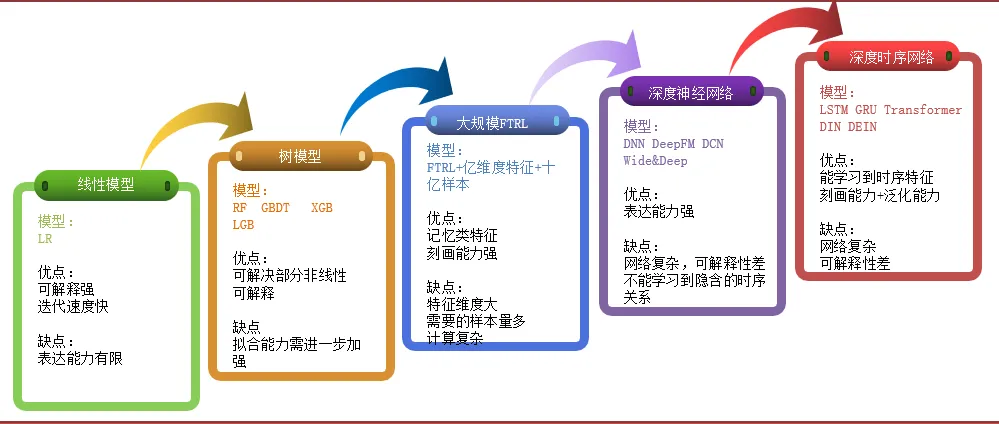
③音乐的高消费成本、前后高关联特性,更加要求有合适的模型去表达用户的需求
如上图所示,我们经历了从一开始的线性模型、到树模型、到大规模 FTRL、再到深度神经网络、最后到深度时序网络,这么一个音乐推荐方面的迭代过程。
首先,我们从 LR 模型入手。该 LR 模型的解释性较强,便于我们进行选择。不过,虽然它的解释性较强、且迭代的速度较快,但是它的表达能力是非常有限的。
后来,我们转到了树模型。该模型中的 RF 和 LGB 等模型具有:能够解决部分非线性可解释的优点,当然其缺点在于拟合能力有待加强。
接着,我们上马了适合表达的大规模 FTRL。其优点在于:可以通过记忆类特征,基于之前的学习和时序训练,表达并刻画出所有的特征与关联性。
而缺点则是特征纬度比较大,即:对于来自不同公司的不同需求,需要的样本量会比较多,计算量也会比较复杂。
为了增加后续的表达能力,我们采用了深度神经网络,包括:DNN、DeepFM 以及 Wide&Deep 等模型。
它们的优点是理论性非常强,而缺点是:由于本身神经网络的复杂性,因此它们的可解释性比较差,也不能学习到各种隐含的时序关系。
最后,我们采用了深度时序网络,其对应的模型包括:LSTM、GRU Transformer、DIN 以及 DEIN,它们的优点是能够学习到不同的时序特征,进而具有刻画+泛化的能力。
当然,它们同样带有上述提到的深度神经网络的缺点,即:网络比较复杂,而且可解释性比较差。
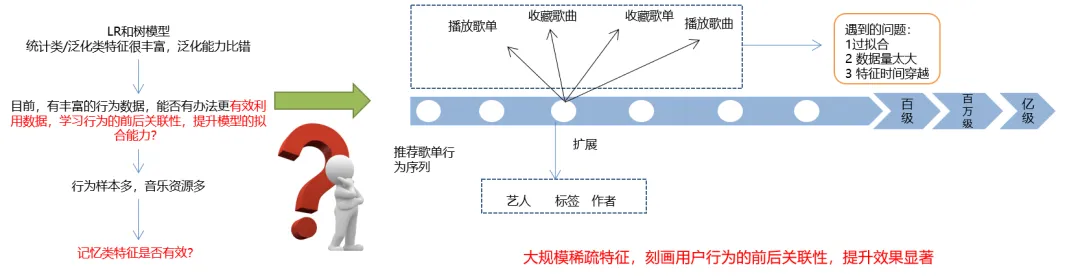
我们下面来看看 LR 以及树的模型。前面我们说过,线性与树模型的特点是:统计类/泛化类特征很丰富,但是泛化能力比较差。
在歌曲应用场景中,我们可以直接把与歌曲相关的、由用户行为所产生的丰富数据,提供给该模型。
通过算法,我们需要将各种音乐指标抽象成标签。可是,虽然我们有足够多的音乐资源和行为样本,但是由于行为序列往往不是线性的,因此我们反而遇到了过拟合、以及特征时间穿梭(即特征记忆)方面的问题。
我们亟待通过线下与线上的特征一致性,来有效地利用数据,学习不同行为的前后关联性,进而提升模型的拟合能力。
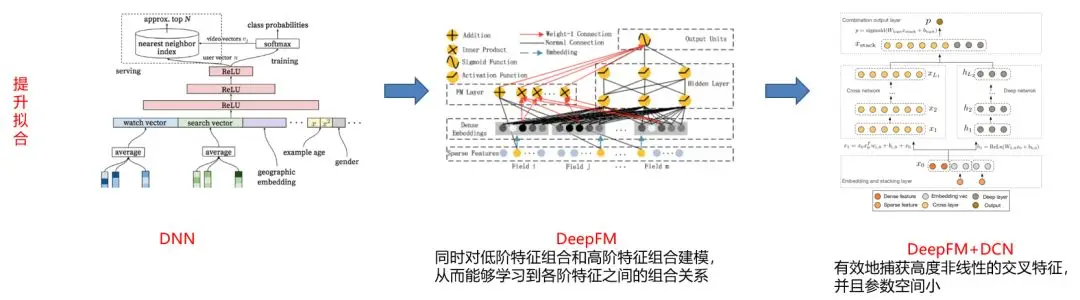
因此,为了提升拟合能力,我们首先尝试的是 DNN 模型。DNN 在结构上是通过 ReLU 来保证对于低阶特征组合和高阶特征组合的全连接,但是这也导致了整体数量的膨胀。
于是,我们改进为 DeepFM,它能够同时对低阶特征组合和高阶特征的组合进行建模,从而能够学习到各阶特征之间的组合关系。如上图所示,我们在后期还引入了 DCN。
DCN 可以显式地学习高阶特征的交互。我们可以籍此来有效地捕获高度非线性的交叉特征。
由于仍保持了 DeepFM 模型,我们可以有效地控制向量的扩张,从而让参数的空间得以缩小。
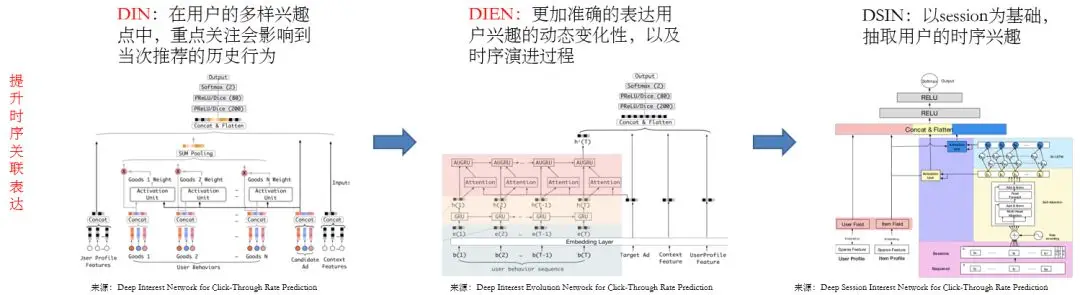
在前文中,我们也提及了时序关联表达的问题。对此,我们曾经采用过针对点击率的 DIN(Deep Interest Network)。
在用户的多样化兴趣点中,DIN 重点关注的是那些会影响到当前推荐的历史行为。不过,DIN 无法捕获用户对于音乐兴趣类型的动态变化。
例如,某个用户以前喜欢电声类音乐,后来改为喜欢民谣了。那么此类“演进”正是 DIN 所无法捕获的。
在此基础上,我们改用到了深度兴趣演化网络(DIEN)模型。该模型的主要特点是:通过关注用户在系统中的兴趣演化过程,设计了兴趣抽取层与进化层。
它采用新的网络结果和建模形式,来更精确地表达用户兴趣的动态变化,以及时序演进的过程。
为了更加细粒度地掌握用户的兴趣变化,我们还运用了 DSIN 模型。DSIN 主要由两部分构成:一个是稀疏特性,另一个是处理用户行为序列。
该模型能够发现某个用户在同一个 Session 中,所浏览商品的相似性;以及在不同 Session 中,所浏览商品的差异性,进而抽取用户的时序兴趣。
④在音乐消费中,鉴于用户需求的复杂性,很难用单一目标去衡量音乐推荐系统的优劣
虽说推荐系统是一个典型的统计学应用,但是统计学只能解决 95% 的问题,剩下的 5% 是有关个人偏好方面的。
我们在实际应用中往往会遇到各种问题,其中包括:CTR(Click-Through-Rate,点击率)与消费时长的关系并非同步提升,有时候甚至呈现出此消彼长的趋势。那么我们该怎么解决多目标的问题呢?

针对多目标问题,我们有许多种解决方法可供选择。如上图所示,有:样本加权、Weight Loss、以及部分网络共享。因此,我们采用了多目标联合训练,这种简单的实现方式。
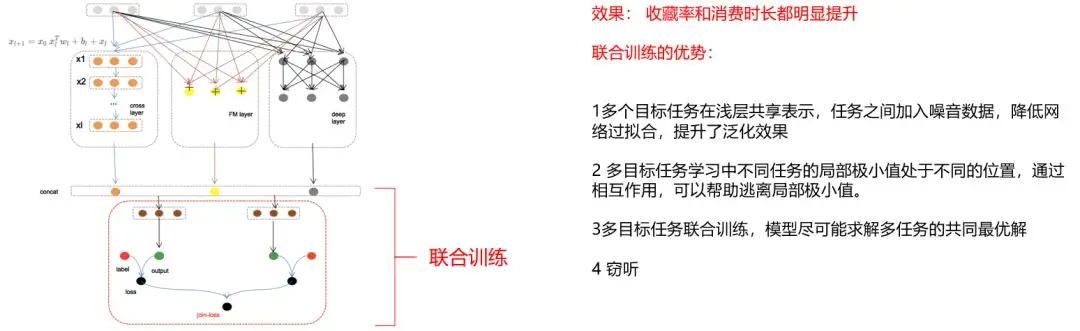
在上图中,我们首先在网络层保证了各项输出,并实现了浅层共享表示。因此,在训练效果上,虽然目标之间也存在一定的差异性,但是随着我们引入了差异网络进行训练,收藏率和消费时长都得到了明显的提升。
可见,联合训练的优势在于:
通过多个目标任务在浅层共享表示,我们在任务之间加入了噪音数据。此举既降低了网络过拟合,又提升了泛化的效果。
在多目标任务的学习中,我们通过让不同任务的局部极小值处于不同的位置,并能够相互作用,以协助逃离局部的极小值。
通过多目标任务的联合训练,让模型尽可能地去求解多任务的共同最优解。
使用类似于“窃听”的方式,跟踪用户对于音乐的收藏等操作,进而做出相应的判断。
回顾我们在前文中所提到的音乐推荐与其他类型推荐的差异点,我们实现了如下点对点式的解决方案:
差异:基于音乐本身的复杂性,我们该如何理解音乐资源呢?解决:利用 NLP、视频、以及图像技术去更好地理解音乐。
差异:可重复消费与不可重复消费的不同之处。解决:利用音乐的消费特性,去智能地分析不同歌曲之间的关联性。
差异:各种音乐不但消费的成本较高,而且前后有着明显的关联性。另外,有效行为的含义往往会更加丰富。解决:利用复杂的 AI 模型,去探究用户听歌的序列关联性。
差异:很难采用单一的目标,去衡量音乐推荐系统的效果。解决:利用 MTL 技术,去解决用户的多样性需求。
那么,音乐场景为什么一定需要 AI 呢?显然,如今已经不是过去那种靠买 CD、唱片听歌的端到端时代了。
在我们的音乐推荐平台上有着亿万个用户。他们在不同的心情状态下,面对由十万多个音乐人产生的千万多首音乐作品,需要通过美好的音乐来获取良好的心情。
我们可以毫不夸张地说:“耳机是互联网时代的输氧管,而音乐则是氧气。”

因此,我们需要在一个 4 维的空间内,解决复杂的匹配问题。而这正是人工智能的用武之地。
通过基于 AI 的推荐系统,我们能够不断提供强大的长尾发掘能力和精准的匹配能力,进而在不断提升用户体验的同时,来促进他们自愿分享和发掘网易云音乐平台上更多的歌曲资源。
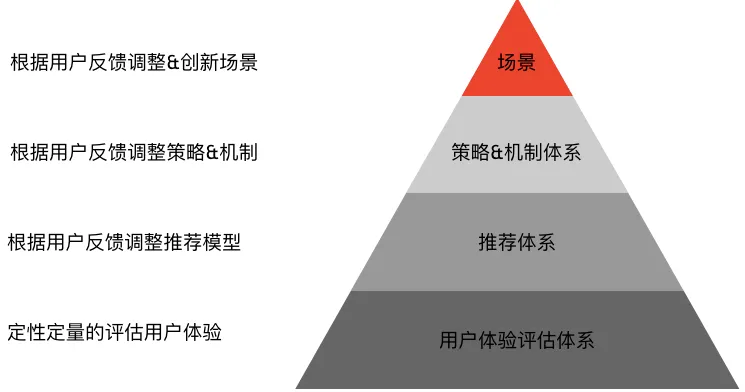
为了达到上述目的,我们建立了一个如上图所示的体系结构。具体包括如下方面:
用户心智模型体系。包括:行为、认知、态度等。
用户调研体系。包括:调研问卷等。
Case 分析体系。包括:分析用户、及用户群的使用行为。
评估指标体系。包括:收藏率、切歌率、以及使用时长等。
数据反馈体系。包括:收藏、切歌、离开等正负向反馈。
通过这些定性和定量的用户体验评估体系,我们采用知识图谱、统计学习、以及强化学习相结合的方式,构建出了如下的三层模型体系:
排序体系。包含:排序模型、ee 模型、以及流行趋势模型。
匹配体系。包含:行为推荐模型、以及新内容发现模型。
数据体系。包含:行为数据、用户画像、以及内容画像。
通过上述这些,我们不断掌握与用户相关的数据知识、乃至专家知识,从而更好地提升了平台的针对性和用户的接受程度。
CIO之家 www.ciozj.com 公众号:imciow