谈到用户画像,大体可以用俩个词概述"persona" 和 "profile"。两者区别在于使用者的差异。Persona也叫做用户角色,是描绘抽象一个自然人的属性,主要是讨论产品、需求、场景、用户体验的时候使用。Profile是和数据挖掘、大数据息息相关的应用,通过数据建立描绘用户的标签,主要是运营和数据分析师使用。本文重点讲述profile的构建
之家从16年开始构建自己的用户画像至今已有5年时间,期间有过多种尝试。整体的用户画像逻辑架构如图所示。
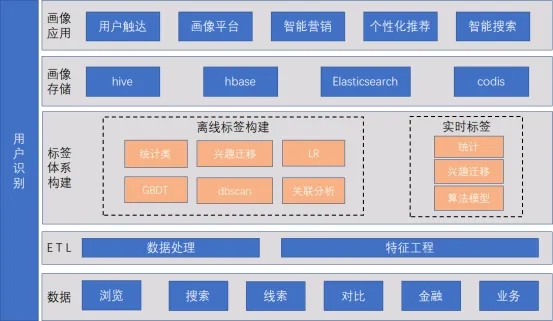
主要从用户识别、标签体系、画像构建、画像存储、画像质量五个方面来进行介绍
一、用户识别
在PC为主流触点的阶段,企业期望存在上帝视角,能了解用户的在网络上的完整旅程,但由于弱账号体系的弊端无法实现,逐步推进了idmapping技术的发展。之家在这个过程中的的技术演变紧随行业发展,由最大联通子图生成uuid 到 强关系+独立账号。
id-mapping 期望的上帝视角
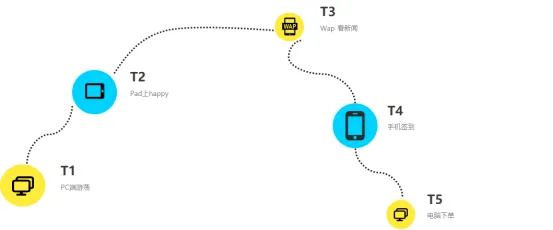
第一阶段,id-mapping 为账号之间的联通子图(v1.0)。具体实现方案为迭代染色算法(分布式并查集)实现。
该方案存在两个问题,其一,打通率比较低,由于需要关系在数据中得到体现(如用户登录 userid与cookie之间的关系);其二,存在多人共用电脑导致关系的错连。但对于无法打通的用户行为,这种实现方式可以基本的满足企业的业务需求。
随着移动互联的大热,app端的在业务中的占比越来越重,上述问题越来越凸显,由于错连多连导致用户画像标签比较难以解释,经常出现“我没看过这个车系,为什么我有这个车系兴趣”等等,对画像的应用推进与推荐系统的解释造成了很多困扰。
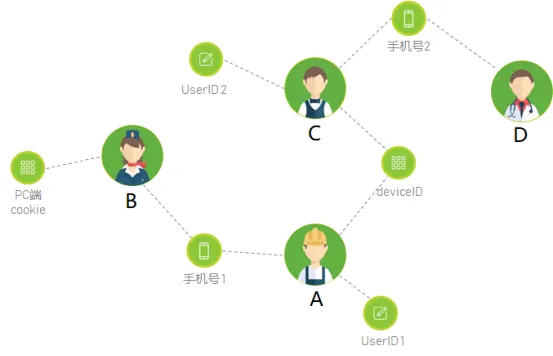
第二阶段,id-mapping 为强关系+独立账号 (v2.0),也是现在之家用户画像构建时采用的用户识别。强关系是指用户账号存在主次,用户的打通以userid 和 phone 分别做为主账号,pc-cookie、m-cookie、deviceid作为附属账号,通过账号一度关系进行打通,保证“用户”的准确性。独立账号是指在用户画像构建中对于pc-cookie、m-cookie、deviceid、userid、phone 都作为独立用户分别构建自己的画像标签。两者相结合塑造完整的互联网人。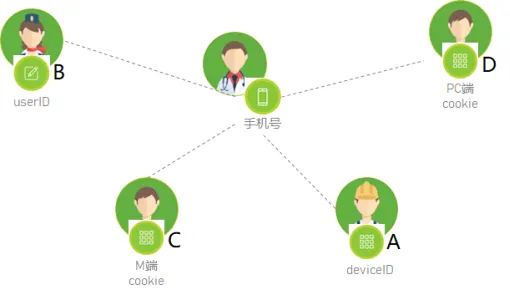
二、标签体系
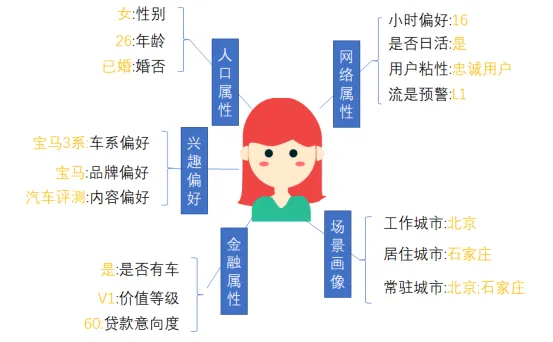
用户画像的构建过程比较乏味,标签体系是从乏味的标签中抽象出的一个逻辑架构体系。简单说就是把用户标签分列到不同的类里面,这些类都是什么(标签如性别),彼此之间有何联系,就构成了标签体系。标签体系的构建大同小异,基本包括人口属性、网络属性、地理位置、兴趣偏好、商业(金融属性)、业务属性。
用户标签体系的构建过程可以分为两个阶段,规划驱动阶段与需求驱动阶段。
在规划驱动阶段,构建企业通用的标签逻辑架构,业务部门共用的基准版本用户画像。在之家的构建过程基准本的体系如下:
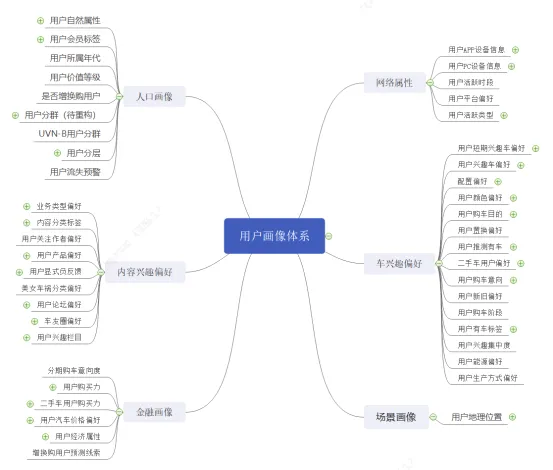
之家通用标签体系
随着画像的应用,通用版本已经无法满足日益多变的场景需求, 如嘿car、小程序、青少年频道、用户增长运营、金融触达、智能推荐等等,场景需要下钻,需要精细化的用户分类颗粒,逐步转化为需求驱动阶段。在该阶段标签构建的差异越来越大,维度也越来越细,构建成千上万的标签。
三、标签构建
1、从构建思路上可以分为:统计类、兴趣类、模型类
a、统计类标签,业务规则,将业务问题转化为数据口径实现
如下收藏列表、搜索关键词、保险到期时间、是否下过线索、30天内访问xx次数等等
b、兴趣类标签,基于兴趣迁移模型构建用户标签。综合考虑特征、特征权重、距今时间、行为次数等因素,用户兴趣标签的构建公式如下:
用户兴趣标签=行为类型权重 * 时间衰减 * 行为次数
特征:需要结合业务选择,如浏览、搜索、线索、对比、互动、点击、有车等行为。
权重:用户在平台上发生的行为具体到用户标签层面有着不同的行为权重,一般而言,行为发生的成本越高权重越大.可以由业务人员确定也可以采用TF-idf的技术分析得出.
时间衰减:用户行为受时间的影响不断减弱,距离现在越远,对用户兴趣的影响越低,这里采用牛顿冷却定律的思想拟合衰减系数,衰减周期结合业务制定
行为次数:在固定时间周期内行为发生的次数越多兴趣倾向越重
另外,用户兴趣权重是表示用户在某一分类(标签)下的兴趣差异并不能作为两个用户兴趣度的比较。所以用户的兴趣标签计算可以采用增量叠加的方式更新.之家兴趣类标签的计算采用自然天增量更新的方式进行落地实现。
c、模型类标签
基于机器学习方法进行数据建模预测用户的标签。整体上这类标签在标签体系中的占比较少。
是否有车基于RF+LR模型实现
常驻地 基于GPS 聚类获取这里采用DBSCAN
购车转化 GBDT
用户分群 KMENAS聚类产生
从数据时效上可以分为离线画像与实时画像,离线与实时采用的构建思想相同,区别在于离线画像描述的使用户长期的习惯,实时画像描述的是用户的当下兴趣,需要结合场景根据批量处理与流式处理的差异做相应调整。
四、画像存储
用户画像数据的存储一般可以分为三类:关系型数据库、NoSQL数据库和数据仓库。在大数据基础上,之家用户画像的存储使用hive、hbase、ES、Codis相结合的方式。不管哪种形式的存储,都遵循本体表示法,以本体模型存储用户的属性和关系。
1、hive存储
使用hive构建画像集市,解耦标签之间关系,数据组织形式简单,简化操作mr计算框架的方式是的便于数据分析人员分析,组织形式为多张hive表存储,每张表中存储部分标签信息。
2、hbase和codis
作用相似,都是将分散的标签数据merge成一个完整的用户肖像,对外提供基于用户id的快速查询。
3、ELasticsearch
同样是将片面的标签信息,刻画出用户肖像,区别在于上层业务场景,主要用于人群圈定,洞察分析、用户触达等
五、画像评测
现代管理学之父彼得·德鲁克说:一个事物,如果你不能衡量它的话,那么你就不能增长它。如果期望构建高质量的用户画像,那就需要建立画像的监控评测体系。首先,业务场景的AB实验是最能体现价值的方式也是在推荐、广告领域应用最广的验证策略。除此之外时效性、覆盖率、准确性也是用户画像重点关注维度。
时效性:对于群体分析,画像的时效并不是特别突出的问题,但对智能推荐、用户转化等场景,对于近期或当下兴趣有着非常高的要求,区分标签场景我们制定并推动了 sla 目标和实时构建
覆盖率:在投放用户触达、营销场景下,标签的覆盖率问题比较突出。但是标签覆盖率的提升有时会牺牲准确性,具体的方案需要结合企业自身的业务需求综合考虑。
准确性:不同类型的标签评估方式不同,统计类标签验证正确性,兴趣类标签验证合理性,模型算法关注auc、F1等指标。其中兴趣偏好标签的合理性验证多为定期抽测,以用户短期行为核验标签结果,相近标签相互印证,公共常识验证人群分布。多角度印证能够整体提升画像标签的质量,提升业务使用画像标签的信心。
另外,探索中的验证方案,对与兴趣标签构建负向兴趣成对出现,验证用户正向兴趣与负向兴趣的差异最大化。
CIO之家 www.ciozj.com 公众号:imciow